
티스토리 뷰
[논문 100개 구현 3탄] Transformer(Attention Is All You Need)
sikaro 2024. 11. 28. 12:30LLM 세대를 연 가히 혁명적인 논문. 필자는 사실 수십번도 더 봤던 논문이다.
그러나 구현 과정에 대해서 자세히 살펴보지 않았었는데, 이번에는 Pytorch 코드를 보면서 어떤 구조로 되어 있는지 정말 정밀하고, 자세하게 살펴보도록 하겠다.
논문 구현에 앞서 확인해야 할 포인트
Read
1. 논문 제목(title)과 초록(abstract), 도표(figures) 읽기
2. 도입(introduction), 결론(conclusion), 도표(figures)를 읽고 필요없는 부분 생략
3. 수식은 처음 읽을 때는 과감하게 생략
4. 이해가 안되는 부분은 빼고 전체적으로 읽는다.
QnA
1. 저자가 뭘 해내고 싶어했는가?
2. 이 연구의 접근에서 중요한 요소는 무엇인가?
3. 당신(논문독자)는 스스로 이 논문을 이용할 수 있는가?
4. 당신이 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
구현하기
1. 수식 이해하고 직접 연산하기
2. 코드 연습하기(오픈소스를 받아 직접 구현)
Read
1. 논문 제목(title)과 초록(abstract), 도표(figures) 읽기
직역하자면 '어텐션만이 당신에게 필요한 모든 것' 정도가 된다.
논문 제목에서부터 보듯, 당시까지 Attension 메커니즘을 그저 RNN이나 LSTM에서 신경망 헬퍼로 써왔던 것에서 탈피해, 모든 신경망을 어텐션만으로 구성해 메커니즘을 만들게 된 게 저작자들의 의도라는 걸 엿볼 수 있다.
초록(abstract)
The best performing models also connect the encoder and decoder through an attention mechanism.
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
기존 시퀀스 모델은 엔코더와 디코더로 되어 있지만 그저 연결하는 것에 불과하다.
우리는 반복(recurrence)과 합성곱(convolution)을 완전히 배제하고, 오직 어텐션 메커니즘에 기반한 새로운 간단한 네트워크 아키텍처인 Transformer를 제안한다.
Abstract에서 주장하는 부분들은 다음과 같다.
- 오직 어텐션 메커니즘만 사용하여, 순환이나 합성곱 없이 전역 의존성을 모델링한다.
- 영어-독일어 및 영어-프랑스어 번역 과제에서 높은 BLEU 점수를 기록하며, 기존 최첨단 성능을 초과.
- 병렬화가 용이하고 훈련 시간이 단축되어 효율적이다.
더 설명이 필요 없이 이미 증명된 논문이기에 다른 건 넘어가도록 하겠다.
2. 도입(introduction), 결론(conclusion), 도표(figures)를 읽고 필요없는 부분 생략
Introduction
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states ht, as a function of the previous hidden state ht−1 and the input for position t. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples. Recent work has achieved significant improvements in computational efficiency through factorization tricks [21] and conditional computation [32], while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
- RNN 기반 모델은 순차적으로 데이터를 처리하므로 병렬화가 어렵고 긴 시퀀스에서는 성능이 제한된다.
- 어텐션 메커니즘은 거리와 관계없이 의존성을 모델링할 수 있어 효과적이나, 기존에는 RNN과 함께 사용됨.
- Transformer는 완전한 어텐션 기반 구조로 설계되어 병렬화와 긴 시퀀스의 의존성 학습을 용이하게 한다.
Figure 1

Figure 1: Transformer의 구조: 인코더와 디코더는 각각 다중 헤드 어텐션 및 피드포워드 네트워크로 구성.
Figure 2: Scaled Dot-Product Attention 및 Multi-Head Attention 개념:
- Scaled Dot-Product Attention은 쿼리와 키의 점곱을 활용하며, 스케일링을 통해 안정성을 증가.
- Multi-Head Attention은 여러 어텐션 레이어를 병렬적으로 실행하여 다양한 표현 학습 가능.
이 부분에 대해서는 코드에서 더 자세히 다뤄보도록 하겠다.
Conclusion
Transformer는 기존의 순환 신경망 기반의 한계를 극복하며, 단순하면서도 강력한 성능을 보인다.
번역 작업에서 최첨단 성능을 기록하며, 훈련 효율성 또한 대폭 개선.
어텐션 기반 모델의 확장 가능성 탐구를 제안하며, 텍스트 외 이미지, 오디오 등의 작업으로의 응용을 기대.
QnA
1. 저자가 뭘 해내고 싶어했는가?
Transformer 모델을 통해 기존 순환 신경망(RNN)과 합성곱 신경망(CNN)의 한계를 극복하고자 하였다. 저자들은 주로 다음과 같은 목표를 가지고 있었다:
- 병렬화 가능성 증대: 순환이나 합성곱 없이 전적으로 어텐션 메커니즘에 의존하여 병렬 처리가 가능하게 함.
- 효율적 훈련: 기존 모델 대비 훈련 시간이 단축되도록 설계.
- 성능 향상: 기계 번역과 같은 작업에서 BLEU 점수와 같은 품질 평가 지표를 개선.
- 일반화 가능성: 영어 구문 분석과 같은 다른 자연어 처리 작업에도 적용 가능성을 입증.
2. 이 연구의 접근에서 중요한 요소는 무엇인가?
- 어텐션 기반 아키텍처: 모델의 중심에는 Scaled Dot-Product Attention과 Multi-Head Attention 메커니즘이 있다.
- 순환 및 합성곱 제거: 모델은 완전히 어텐션에 의존하며, 이를 통해 연산 복잡도와 순차적 병목 문제를 완화.
- 위치 정보 활용: 순환이 없으므로, Positional Encoding을 사용하여 입력 시퀀스의 순서를 모델링.
- 병렬성 최적화: 모델 구조상 모든 입력과 출력을 동시에 처리할 수 있어 긴 시퀀스에서도 효율적.
- 효율적 하드웨어 활용: NVIDIA P100 GPU 8개를 사용하여 3.5일 만에 최고 성능 달성.
3. 당신(논문독자)는 스스로 이 논문을 이용할 수 있는가?
- 영어 구문 분석 등 구조화된 예측 작업에 적합.
- 이미지, 오디오 등의 다양한 입력 데이터 유형으로 모델을 확장 가능.
4. 당신이 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- Bahdanau et al. (2014): Neural machine translation by jointly learning to align and translate (어텐션 메커니즘의 초기 연구).
- Sutskever et al. (2014): Sequence to sequence learning with neural networks (시퀀스-투-시퀀스 모델 개념 소개).
- Luong et al. (2015): Effective approaches to attention-based neural machine translation (어텐션 변형 및 활용 사례).
- Vaswani et al. (2017): Transformer의 발전을 위한 후속 연구 및 GitHub 리소스 활용.
구현하기
대망의 구현 부분에서는 Pytorch에 있는 torch.nn.Transformer를 참고한다.
torch.nn.Transformer
(d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1, activation=, custom_encoder=None, custom_decoder=None, layer_norm_eps=1e-05, batch_first=False, norm_first=False, device=None, dtype=None)
여기서 인풋은 src, 아웃풋은 tgt이다.
transformer_model = nn.Transformer(nhead=16, num_encoder_layers=12)
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))
out = transformer_model(src, tgt)
간단히 만들어지는 코드를 살펴보자.
class Transformer(nn.Module):
def __init__(
self,
num_tokens,
dim_model,
num_heads,
num_encoder_layers,
num_decoder_layers,
dropout_p,
):
super().__init__()
# Layers
self.transformer = nn.Transformer(
d_model=dim_model,
nhead=num_heads,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers,
dropout=dropout_p,
)
def forward(self):
pass
d_model은 인코더와 디코더에서의 정해진 입력과 출력의 크기(Token)(default=512)
num_encoder_layers : 인코더의 층 수(default = 6)
num_decoder_layers : 디코더의 층 수(default =6)
nhead : 멀티헤드 어텐션 모델의 헤드 수(default = 8)
dim_feedforward: FFNN 은닉층 크기(default=2048)
정도이다.
각각 그러면 어떻게 만들어지는가를 처음부터 살펴보자.
1. 엔코더디코더 구조와 트랜스포머
엔코더 디코더 구조의 아키텍처는 다음과 같이 엔코더를 정의해주고, 해당 엔코더로부터 src_mask, tgt_mask를 받아 만들어지는 형태이다.
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)마지막에는 softmax로 해서 확률 값이 나온다.
하지만 트랜스포머는 어텐션으로 된 엔코더와 디코더를 몇 개씩 쌓는 구조이다.
따라서 다음과 같이 for로서 엔코더를 쌓는다.
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
clones 함수:
- 동일한 layer를 N개 복제하여 nn.ModuleList에 저장합니다.
- 이를 통해 동일한 구조의 레이어를 여러 번 사용할 수 있습니다.
Encoder 클래스:
- 입력으로 하나의 레이어(layer)와 레이어의 개수(N)를 받습니다.(아까 default=6)
- self.layers는 clones 함수를 사용하여 복제된 레이어들의 리스트입니다.
- self.norm은 출력에 대해 정규화를 수행하는 LayerNorm입니다.
forward 메서드:
- 입력 x와 마스크 mask를 받아 레이어를 하나씩 순차적으로 통과합니다.
- 각 레이어는 x = layer(x, mask)를 통해 입력을 갱신하며, 마지막으로 정규화된 값을 반환합니다.
여기서 mask에는 src_mask가 들어간다고 생각하면 된다.
이 src_mask는 Multi-head Self-Attention에서 사용된다.
# Forward에서 호출되는 모습
encoder = Encoder(layer, N)
output = encoder(input_tensor, src_mask)
input_tensor: 입력 시퀀스
src_mask: 입력 시퀀스에 적용할 마스크
2. 잔차 연결
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features)) # 학습 가능한 가중치 (기본값 1)
self.b_2 = nn.Parameter(torch.zeros(features)) # 학습 가능한 바이어스 (기본값 0)
self.eps = eps # 안정성을 위한 작은 값 (0으로 나누는 문제 방지)
def forward(self, x):
mean = x.mean(-1, keepdim=True) # 마지막 차원 기준 평균
std = x.std(-1, keepdim=True) # 마지막 차원 기준 표준편차
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
그리고 Tranformer 모델에서의 잔차 연결도 정의해준다.
위에서 LayerNorm함수가 이것이다.
이는 Output = LayerNorm(x+Sublayer(x))로 해당되어 정의되게 된다.
정규화를 통해 학습 안정성을 높이면서, 잔차까지 연결되어 더 깊게 쌓을 수 있게 된다.
들어온 input tensor의 평균과 표준편차를 계산하고, (x-평균)/(표준편차+eps)으로 정규화한다.
학습 가능한 매개변수인 a2와 b2를 사용하여 스케일링 및 이동한다.
LayerNorm(x) = a2 * Normed + b2
그럼 여기까지 보면, Encoder에서의 리턴되는 self.norm(x)는 LayerNorm(x)와 마찬가지가 된다.
3. SubLayer Connection정의
이제 위에 잇던 두 개의 함수를 연결해서 서브 레이어가 잔차 연결이 되도록 만든다.
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size) # 정규화 레이어 (Layer Normalization)
self.dropout = nn.Dropout(dropout) # 드롭아웃 레이어 (Dropout)
def forward(self, x, sublayer):
"""
x: 입력 텐서
sublayer: 적용할 서브 레이어 (예: Self-Attention 또는 Feedforward Network)
1. x를 정규화한다 (LayerNorm).
2. 정규화된 값을 서브 레이어에 전달한다.
3. 서브 레이어의 출력에 Dropout을 적용한다.
4. 원래 입력(x)과 Dropout 처리된 출력을 더한다.
"""
return x + self.dropout(sublayer(self.norm(x)))
그러면 sublayer에서 dropout을 해주고, 원래의 x와 더해서 잔차 연결을 해준다.
정규화된 데이터를 특정 서브 레이어(Self-Attention 또는 Feedforward Network)에 전달하게 된다.
즉, 잔차 연결과 정규화를 하나의 모듈로 만든 것이다.
이건 Resnet에 대한 이해가 필요한데, 간단히 설명하자면 gradient로 만들 때 dx가 0에 가까워지는 문제(vanishing gradient)를 해결하기 위해 기존 x에 잔차를 연결해서 미분하여 더 깊게 쌓을 수 있도록 하는 것이다.
논문 Attention Is All You Need에서는 Layer Normalization을 마지막에 수행한다고 설명하지만, 이 구현에서는 코드 간소화를 위해 먼저 수행한다.
수학적으로 동일한 결과를 얻을 수 있으므로, 실제로는 큰 차이가 없다.
4. Encoder Layer 재정의
그러면 Encoder Layer가 재정의되면 다음과 같이 된다.
앞에 Endoer Class에서 보았던 layer로 전달되었던 부분이 여기서 구체적으로 정의된다.
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn # Self-Attention 모듈
self.feed_forward = feed_forward # Feed Forward 모듈
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size # 입력/출력의 크기
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
- size: 입력/출력 벡터의 차원 (dmodeld_\text{model}).
- self_attn: Multi-head Self-Attention 모듈.
- feed_forward: Position-wise Feedforward Network.
- sublayer: 두 개의 SublayerConnection(잔차 연결 + 정규화 + Dropout).
self_attn에 lambda x를 적용해서 sublayer의 0번 인덱스에 전달한다.
self.sublayer는 clone 함수에서 아까 봤던 대로 2개의 Sublayerconnection 객체로 된 리스트로 이루어져 있을 것이다.
그렇다면 작용은 이렇게 된다.
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))forward 함수에 들어가는 게 x,sublayer다.
즉, (x, lambda x: self.self_attn(x, x, x, mask)면, x하고 sublayer = lambda x:self.self_attn(x,x,x,mask)가 되는 것이다.
#Step 1: 입력 x에 대해 Layer Normalization을 먼저 수행:
normed_x = self.norm(x)
#Step 2: 정규화된 텐서 normed_x를 sublayer로 전달:
sublayer_output = sublayer(normed_x)
#Step 3: Self-Attention 출력에 Dropout 적용:
dropped_output = self.dropout(sublayer_output)
#Step 4: 원래 입력 x와 Dropout 결과를 더해서 최종 출력 생성:
output = x + dropped_output
그러면 당연히도 Step 2에서 lambda x:self.self_attn(x,x,x,mask)로 normed_x가 들어가서 연산된다.
Q = K = V = normed_x
mask는 패딩 토큰 등을 무시하도록 도움을 준다.
마찬가지로 sublayer[1]의 객체에도 피드포워드를 넣어서 반환해준다.
Encoder Layer는 두 개의 주요 서브 레이어로 구성되어 있는데, Self-Attention 서브레이어[0]와 Feed Forward 서브 레이어[1]이 되어 있다.
즉, 셀프 어텐션 중첩을 연산하다가, 해당 x로 결국 Feed Forward를 통과해서 Retrun되게 되어 있다.
여기까지만 이해하면 코드 구조는 진짜 다 이해한거다.
self_attn, feed_forward는 아래 Decoder 부분에서 더 자세히 살펴보자.
5. 디코더 구조
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)디코더 구조도 엔코더 쪽에서 이해했으면 똑같다.
다만, 여기는 서브 레이어가 3개가 생긴다.
디코더 구조는 Self-Attention, Source-Attention(Cross-Attention), Feed Forward 3단계의 처리 과정을 거친다.
여기는 앞서 보았던 encoder에서의 self-Attention 구조와 똑같다. 단, tgt_mask는 미리 본 단어만을 사용하도록 제한된다.
여기서 주목해야 할 점이 있는데, tgt_mask를 사용하는 Self-Attention 서브 레이어가 현재 위치 이후의 단어들을 참조하지 못하도록 한다는 사실이다.
왜 일까? 그 이유는 순차적인 예측을 보장하기 위해서이다.
디코더의 각 단어가 자기 자신과 그 이전의 단어들에만 의존하고, 현재 위치의 단어는 그 뒤에 올 단어들에 대한 정보를 사용해서 예측할 수 없도록 해야 한다.
예를 들어, tgt_mask[0, 0] = 1은 첫 번째 단어가 자신을 참조할 수 있다는 뜻이고, tgt_mask[0, 1] = 0은 첫 번째 단어가 두 번째 단어를 참조하지 못하도록 한다.
이 방식은 GPT 모델의 원리를 알고 있으면 역으로 생각이 가능하다. GPT가 Transformer의 Decoder를 이용해서 만든 모델인데, 앞의 단어를 보고 뒤의 단어를 확률론적으로 예측하게 만들 수 있는 부분이 이 부분이기 때문이다.
즉, 시계열적인 처리를 위해 일부러 이렇게 막은 것이다.
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size) # 1 x size x size 형태의 Attention 마스크를 만듦
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8') # 상삼각 행렬 생성 (k=1은 대각선 위)
return torch.from_numpy(subsequent_mask) == 0 # 마스크에서 '1'을 '0'으로, 나머지 '0'을 '1'로 반환
그래서 tgt mask는 나중에 Batch 단계에서 이 subsequent_mask에 감짜져서 들어가게 된다.
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
return tgt_mask
두 번째로 볼 것은
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
부분이다.
Cross-Attention은 인코더의 출력에 대한 Attention이다.
인코더에서 나온 정보를 활용하여 타겟 시퀀스에 대한 정보를 예측하는 데 사용하게 된다.
이 부분은 정보 예측을 돕고 가중치를 조절해주는 부분이라고 생각하면 쉽다.
특이한 점은 src_mask의 memory를 활용해 디코더의 입력(x)가 어디를 참조할지 결정한다는 것이다.
즉, 여기서 m 자체가 인코더의 출력이라고 보면된다.
6. Attention 구현
가장 중요한 부분이다.
여기를 모르면 앞에 있는 것들은 사실 껍데기에 불과하다.
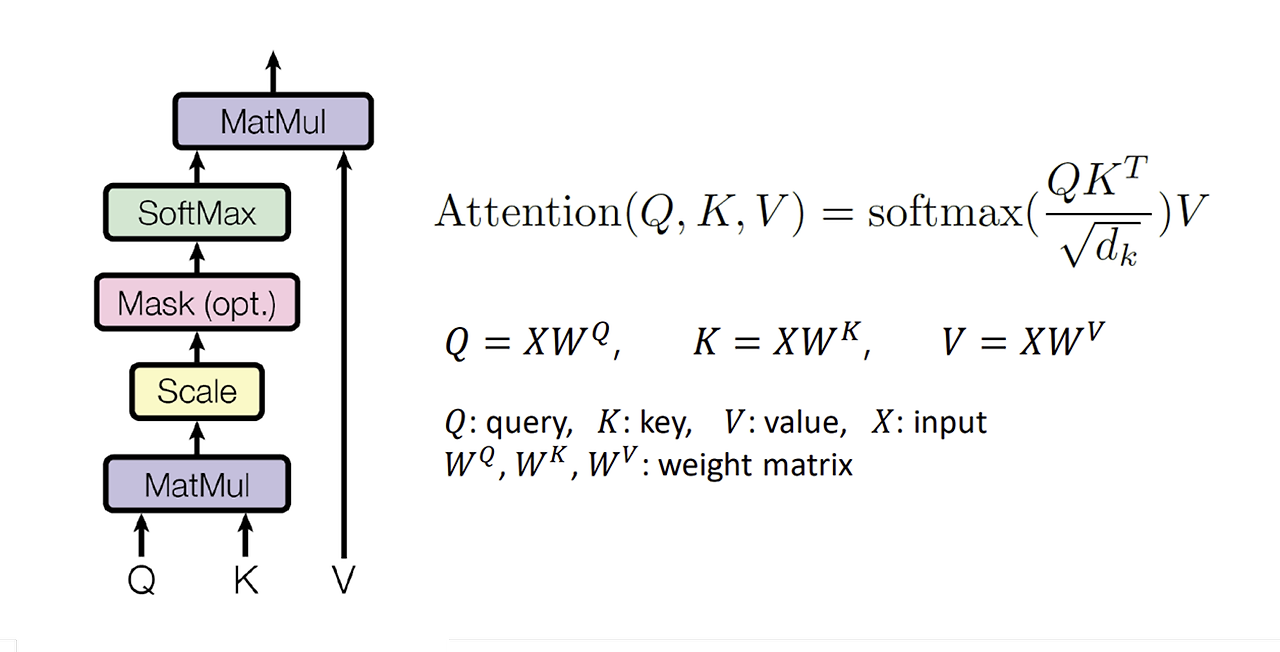
어텐션의 구조는 계산하고자 하는 값 쿼리(Query), 유사도를 계산할 대상 키(Key), 어텐션 결과로 반영될 Value(가중치를 결정하는 값으로 이해하면 쉬움)로 나눠진다.
mask는 어텐션을 계산할 때 어떤 값들을 무시할지 지정한다(여기서 미래의 단어들을 참조하지 않도록 한다)
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
따라서 위의 코드는 다음과 같이 진행된다.
쿼리와 키의 내적 (Dot Product) 계산:
d_k = query.size(-1) # 쿼리 벡터의 차원 크기
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
- query와 key 벡터를 내적(matmul)하여 어텐션 점수(scores)를 계산합니다.
- key.transpose(-2, -1)는 키 행렬을 전치시켜서, 각 쿼리 벡터와 각 키 벡터 간의 내적을 계산할 수 있게 합니다.
- 이 점수는 스케일링을 적용하는데, d_k는 쿼리 벡터의 크기이므로, 이 값을 **sqrt(d_k)**로 나누어 점수의 크기를 안정화시킵니다. 이 스케일링은 너무 큰 값을 방지하는 역할을 합니다.
마스크 적용:
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
- 마스크(mask)가 제공되면, 마스크 값이 0인 곳에 대해 어텐션 점수를 -1e9로 설정하여 해당 부분에 대한 어텐션을 무시합니다. 이 방식은 Softmax 연산에서 해당 값이 0으로 처리되게 합니다.
- 예를 들어, 디코더에서 미래의 단어들을 참조하지 못하도록 하는 마스크가 적용됩니다.
Softmax를 사용하여 어텐션 가중치 계산:
p_attn = F.softmax(scores, dim=-1)
- 어텐션 점수(scores)에 대해 Softmax를 적용하여 확률을 구합니다.
- dim=-1은 마지막 차원(각 쿼리 벡터에 대해)에서 Softmax를 적용하라는 뜻입니다. 즉, 각 쿼리 벡터가 각각의 키 벡터에 얼마나 주의를 기울여야 할지를 나타내는 가중치를 계산합니다.
드롭아웃 적용은 선택 사항
어텐션 출력 계산:
return torch.matmul(p_attn, value), p_attn
- 마지막으로, 어텐션 가중치(p_attn)와 값(value)를 내적하여 최종 어텐션 출력(torch.matmul(p_attn, value))을 계산합니다.
- 어텐션 가중치(p_attn)와 함께 반환하는 이유는 어텐션 가중치가 나중에 분석이나 시각화 등에 사용될 수 있기 때문입니다.
이해가 어렵다면 아래의 예시를 참고하자.
예시 데이터:
각 단어를 임베딩 벡터로 표현했을 때, 간단한 예시로 쿼리, 키, 값을 다음과 같이 설정해보겠습니다.
- 쿼리:
- "사과" → [1, 0]
- "바나나" → [0, 1]
- "키위" → [1, 1]
- 키:
- "사과" → [1, 0]
- "바나나" → [0, 1]
- "키위" → [1, 1]
- 값:
- "사과" → [1, 0]
- "바나나" → [0, 1]
- "키위" → [1, 1]
1. 쿼리와 키의 내적 계산
우리는 쿼리와 키 벡터 간의 **내적(dot product)**을 계산하여 어텐션 점수를 구합니다. 내적은 두 벡터 간의 유사도를 측정하는 방법입니다. 예를 들어, 쿼리 벡터와 키 벡터의 내적을 계산하면 다음과 같습니다.
"사과" 쿼리와 다른 단어들의 키 벡터 내적:
- 사과 (쿼리)와 사과 (키) 내적:(1×1)+(0×0)=1(1 \times 1) + (0 \times 0) = 1
- 사과 (쿼리)와 바나나 (키) 내적:(1×0)+(0×1)=0(1 \times 0) + (0 \times 1) = 0
- 사과 (쿼리)와 키위 (키) 내적:(1×1)+(0×1)=1(1 \times 1) + (0 \times 1) = 1
이렇게, 사과라는 쿼리가 각 단어의 키 벡터들과 내적을 계산하여 점수(1, 0, 1)를 얻습니다.
2. 점수 스케일링
어텐션 점수를 안정화하기 위해 쿼리 벡터 차원 크기(d_k, 예를 들어 2)로 나눕니다. 즉, 점수를 sqrt(d_k)로 나누어 스케일링을 합니다. 여기서 d_k = 2이므로, 내적 점수를 sqrt(2)로 나눕니다.
- 사과 (쿼리)와 사과 (키) 내적 점수: 1/sqrt{2}=
- 사과 (쿼리)와 바나나 (키) 내적 점수: 0/sqrt{2}
- 사과 (쿼리)와 키위 (키) 내적 점수: 1/sqrt{2}
3. Softmax를 통한 가중치 계산
이제 Softmax를 사용하여 점수를 확률로 변환합니다. Softmax는 입력 값의 상대적인 중요도를 계산해주는 함수입니다. 이를 통해 각 단어에 대한 어텐션 가중치를 얻을 수 있습니다.
"사과" 쿼리에 대한 Softmax:
점수는 [0.707,0,0.707]이었으므로, 이 값을 Softmax에 넣으면 다음과 같은 가중치가 계산됩니다.
- Softmax([0.707, 0, 0.707]) → [0.422,0.156,0.422]
따라서 **"사과"**에 대해, "사과"와 "키위"를 더 주의 깊게 보고, "바나나"는 덜 주의하게 됩니다. 이 가중치들이 어텐션 가중치입니다.
4. 어텐션 출력 계산
최종적으로, 어텐션 가중치를 각 **값(value)**에 곱하여, 가중합을 구합니다.
예를 들어, "사과" 쿼리에서 계산된 어텐션 가중치([0.422, 0.156, 0.422])를 각 값 벡터에 곱하고 더하면 최종 어텐션 출력이 나옵니다.
- 사과 값: [1,0]
- 바나나 값: [0,1]
- 키위 값: [1,1]
최종 어텐션 출력:
0.422×[1,0]+0.156×[0,1]+0.422×[1,1]=

농담으로 던졌지만, 진짜로 수학적인 구조만 이해하면 쉽게 이해할 수 있다.
단계별로 생각해서 꼭 분할정복해보자.
7. 멀티헤드 어텐션
드디어 대망의 멀티헤드 어텐션이다.
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0 # 모델 차원이 헤드 수로 나누어 떨어져야 함
self.d_k = d_model // h # 각 헤드의 차원 (d_k)
self.h = h # 헤드의 수
self.linears = clones(nn.Linear(d_model, d_model), 4) # 4개의 선형 변환
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
mask = mask.unsqueeze(1) # mask 크기 확장
nbatches = query.size(0) # 배치 크기
# 1) 쿼리, 키, 값을 각 헤드 차원으로 프로젝션
query, key, value = [
l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))
]
# `query`, `key`, `value`는 (배치 크기, 헤드 수, 시퀀스 길이, d_k) 형태
# 2) 각 헤드에 대해 어텐션 계산
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) 어텐션 출력을 결합하고, 마지막 선형 변환을 적용
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x) # 결합된 텐서를 최종 선형 변환뭐라뭐라 많지만, 이것도 요약해보면 다음과 같다.
여러 개의 어텐션 헤드(예: 8개의 헤드)와 함께 동작하며, 각 헤드는 다른 차원의 쿼리(Query), 키(Key), 값(Value)를 처리합니다. 이러한 각 헤드의 출력을 최종적으로 합쳐서 하나의 어텐션 출력을 만듭니다.
즉, 쫄 거 없이 위의 attention 함수만 이해했다면 그냥 쿼리를 배치 사이즈로 잘라서 어텐션 함수를 통과시켜 처리했다가 다시 합친다고 보면 된다.
- 배치 차원(nbatches): 입력 텐서에서 배치 크기는 따로 처리되어, 여러 샘플이 한 번에 처리될 수 있게 됩니다.
- 헤드 차원(h): 각 헤드는 독립적으로 어텐션을 계산하며, 계산 후에는 결합하여 하나의 출력 텐서를 만듭니다.
- 결합: 각 헤드에서 나온 결과를 view와 transpose로 처리하여 결합하고, 마지막에 다시 선형 변환을 통해 최종 출력을 도출합니다.
def forward(self, query, key, value, mask=None):
if mask is not None:
mask = mask.unsqueeze(1) # mask 크기 확장
nbatches = query.size(0) # 배치 크기query는 보통 다음과 같이 들어간다.
(32,10,512) = query.size(0), query.size(1), query.size(2)
배치 크기, 시퀀스 길이(각 배치에서 처리할 단어 수), 모델 차원(dim)
즉 여기서는 32배치이다.
그 후에는 이렇게 된다.
1. 선형 변환
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]여기서 각 query, key, value 텐서는 nn.Linear 레이어를 통과합니다.
그 후, view와 transpose를 사용하여 각 텐서를 (배치 크기, 헤드 수, 시퀀스 길이, 차원 크기) 형태로 변환합니다. 변환된 텐서들은 각 헤드에 대해 별도의 어텐션을 수행할 수 있도록 준비됩니다.
- view(nbatches, -1, self.h, self.d_k)는 각 텐서를 (배치 크기, 시퀀스 길이, 헤드 수, 차원 크기) 형태로 변환합니다.
- transpose(1, 2)는 시퀀스 길이와 헤드 수 차원을 바꾸어 (배치 크기, 헤드 수, 시퀀스 길이, 차원 크기)로 만듭니다.
2. 어텐션 계산
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)위에서 봤으므로 생략
self.attn은 어텐션 가중치이다.
3. 어텐션 결과 결합
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
각 헤드에서 계산된 어텐션 결과는 x로 저장되며, transpose와 view를 통해 (배치 크기, 시퀀스 길이, 헤드 수 * 차원 크기) 형태로 변환됩니다. 이를 통해 여러 헤드에서 나온 어텐션 결과를 하나로 결합합니다.
4. 최종 선형 변환
return self.linears[-1](x)결합된 어텐션 결과에 마지막 선형 변환(self.linears[-1])을 적용하여 최종 출력을 반환합니다.
선형 변환을 해주는 이유는 멀티헤드 어텐션에서 각 헤드가 다양한 서브스페이스를 학습하고 이를 종합적으로 반영할 수 있게 하기 위해서입니다. 멀티헤드 어텐션은 모델이 입력 데이터를 여러 관점에서 동시에 처리할 수 있도록 하며, 이 과정에서 각 헤드는 다양한 특성을 학습하게 됩니다. 이를 위해서 선형 변환이 필요합니다.
이제 여기까지 이해했다면 나머지 코드들은 보기만 해도 감이 잡힐 것이다. 고로 빠르게 넘어가도록 하겠다.
8. Position-wise Feed-Forward Network
- 각 위치에서 독립적인 변환: 이 네트워크는 입력 텐서의 각 위치에 대해 동일한 변환을 적용합니다. 즉, 문장의 각 단어는 독립적으로 처리되며, 이를 통해 모델은 각 단어의 특성을 더욱 잘 파악할 수 있습니다.
- 비선형성 추가: ReLU 활성화 함수는 비선형성을 모델에 추가하여 더 복잡한 패턴을 학습할 수 있게 만듭니다. 이를 통해 모델은 더 풍부한 표현을 학습하게 됩니다.
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff) # 첫 번째 선형 변환 (d_model → d_ff)
self.w_2 = nn.Linear(d_ff, d_model) # 두 번째 선형 변환 (d_ff → d_model)
self.dropout = nn.Dropout(dropout) # 드롭아웃 레이어
def forward(self, x):
# x에 대해 ReLU 활성화와 드롭아웃을 적용하고 두 번째 선형 변환을 수행
return self.w_2(self.dropout(F.relu(self.w_1(x))))
9. Embeddings and Softmax
- 입력 임베딩: 모델의 입력 토큰을 고차원의 벡터로 변환하여 모델이 이해할 수 있도록 합니다. 이 과정은 각 단어 또는 토큰을 d_model 차원의 벡터로 매핑합니다.
- 출력 임베딩: 디코더의 출력을 다시 단어 확률로 변환하는 과정입니다. 소프트맥스 함수를 사용하여 예측된 토큰에 대한 확률을 계산합니다.
- 임베딩과 소프트맥스 공유: 모델은 입력 임베딩과 출력 임베딩에 동일한 가중치 행렬을 사용하여 파라미터 수를 줄이고 효율성을 높입니다.
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model) # 임베딩 층 정의
self.d_model = d_model # 모델 차원
def forward(self, x):
# 입력 x를 임베딩 후, sqrt(d_model)을 곱함
return self.lut(x) * math.sqrt(self.d_model)
10. 대망의 Positional Encoding
Positional Encoding의 역할
- Transformer는 RNN이나 CNN처럼 순차적 처리(즉, 이전 상태를 고려하여 현재 상태를 처리하는 방식)를 하지 않기 때문에, 시퀀스 내 각 단어가 어떤 위치에 있는지 정보를 추가적으로 인코딩해야 합니다.
- 이를 위해 **위치 인코딩(Positional Encoding)**을 입력 임베딩에 더하여 단어들의 순서 정보를 제공합니다.
- 위치 인코딩은 sinusoidal 함수(사인 함수와 코사인 함수)를 이용하여 각 단어의 위치 정보를 다양한 주파수로 변환합니다.
위치 인코딩 수식
- 각 위치 pos에 대해 짝수 차원에는 sin 함수를, 홀수 차원에는 cos 함수를 적용합니다.
- 수식:

- 여기서 pos는 단어의 위치, i는 인코딩 차원이고, d_model은 모델의 차원입니다. 이 식은 주파수가 기하급수적으로 증가하는 sine/cosine 함수를 사용하여 위치 인코딩을 생성합니다.
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model) # max_len은 위치의 최대 길이
position = torch.arange(0, max_len).unsqueeze(1) # 위치 인덱스
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model)) # 주파수 계산
# 짝수 차원에는 sin, 홀수 차원에는 cos을 사용
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # 배치 차원을 추가
self.register_buffer('pe', pe) # 모델 학습 중 업데이트하지 않도록 buffer로 저장
def forward(self, x):
# 입력 임베딩에 위치 인코딩을 더하고 dropout을 적용
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
세부 설명
- max_len과 d_model:
- max_len: 시퀀스의 최대 길이입니다. 예를 들어, 문장 길이가 5000 이하라면 최대 길이를 5000으로 설정할 수 있습니다.
- d_model: 모델의 차원으로, 위치 인코딩 벡터의 차원 수입니다. 예를 들어, 512 차원의 임베딩을 사용한다면, d_model은 512입니다.
- position:
- position = torch.arange(0, max_len).unsqueeze(1)은 각 위치에 대한 인덱스를 생성합니다. 예를 들어, max_len=5000일 경우, position은 5000x1 형태로 0, 1, 2, ..., 4999의 값을 갖습니다.
- div_term:
- div_term은 주파수의 크기를 계산하는 부분으로, 각 차원에 대해 다른 주파수 값을 생성합니다. 10000이라는 상수를 사용하여 기하급수적인 주파수 변화를 생성합니다.
- pe[:, 0::2] = torch.sin(position * div_term):
- 짝수 차원(0, 2, 4, ...)에 대해 sin 함수를 적용하여 위치 인코딩을 계산합니다.
- pe[:, 1::2] = torch.cos(position * div_term):
- 홀수 차원(1, 3, 5, ...)에 대해 cos 함수를 적용하여 위치 인코딩을 계산합니다.
- self.register_buffer('pe', pe):
- pe는 학습 가능한 파라미터가 아니므로, 학습 중 업데이트되지 않도록 register_buffer로 저장합니다. 이는 모델의 일부로 포함되지만 학습 가능한 파라미터는 아닙니다.
- forward(self, x):
- 입력 x는 이미 임베딩된 토큰들의 벡터입니다. 이 벡터에 위치 인코딩(pe)을 더합니다.
- 위치 인코딩은 각 시퀀스의 길이에 맞춰 자르고(self.pe[:, :x.size(1)]), 이를 입력 벡터에 더한 후 dropout을 적용하여 반환합니다.
예시
입력 시퀀스의 임베딩 벡터가 (batch_size, sequence_length, d_model) 형태일 때, 위치 인코딩이 이 벡터에 더해져서 각 단어의 위치 정보가 포함된 벡터가 됩니다.
왜 이렇게 하는가?
- Transformer 모델은 순서 정보를 처리하는 구조가 없기 때문에, sine/cosine 함수를 이용하여 각 단어의 위치 정보를 고정된 방식으로 인코딩하고 이를 입력 벡터에 더하여 모델에 제공함으로써 순서에 대한 정보를 전달합니다.
- 이 방식은 선형적인 관계를 유지하면서 상대적인 위치 정보를 쉽게 학습할 수 있도록 합니다.
거의 다 왔다. 이제 모델 연결만 해주면 된다.
Full Model
def make_model(src_vocab, tgt_vocab, N=6,
d_model=512, d_ff=2048, h=8, dropout=0.1):
"Helper: Construct a model from hyperparameters."
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn),
c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform(p)
return model구성 요소 생성
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
- attn = MultiHeadedAttention(h, d_model)
멀티헤드 어텐션을 생성합니다. h는 헤드 수, d_model은 모델 차원입니다. 멀티헤드 어텐션은 입력 쿼리, 키, 값을 여러 개의 헤드로 나누어 병렬 처리합니다. - ff = PositionwiseFeedForward(d_model, d_ff, dropout)
Position-wise Feed-Forward Network을 생성합니다. d_model은 모델 차원, d_ff는 피드포워드 네트워크의 차원이며, dropout은 드롭아웃 비율입니다. 이 네트워크는 입력의 각 위치마다 독립적으로 처리됩니다. - position = PositionalEncoding(d_model, dropout)
위치 인코딩을 생성합니다. 위치 인코딩은 시퀀스의 단어 순서를 모델이 이해할 수 있도록 돕는 정보입니다. d_model은 위치 인코딩의 차원, dropout은 드롭아웃 비율입니다.
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
모델 생성
- EncoderDecoder: Encoder-Decoder 구조로 모델을 생성합니다.
- Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N):
- 인코더는 EncoderLayer로 구성됩니다. 각 레이어는 멀티헤드 어텐션 (attn)과 피드포워드 네트워크 (ff)를 포함합니다. N은 인코더의 층 수입니다.
- Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N):
- 디코더는 DecoderLayer로 구성됩니다. 각 레이어는 멀티헤드 어텐션 (쿼리와 키-값을 모두 처리하는 attn 두 번 사용)과 피드포워드 네트워크 (ff)를 포함합니다.
- Embeddings(d_model, src_vocab):
- 입력 단어들을 임베딩 벡터로 변환합니다. src_vocab은 입력 언어의 어휘 크기입니다.
- Embeddings(d_model, tgt_vocab):
- 출력 단어들을 임베딩 벡터로 변환합니다. tgt_vocab은 출력 언어의 어휘 크기입니다.
- Generator(d_model, tgt_vocab):
- 디코더의 출력에서 다음 단어를 예측하는 출력층을 생성합니다. 이는 소프트맥스 함수로 예측 확률을 출력합니다.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform(p)
모델 초기화
- Xavier 초기화를 사용하여 가중치를 초기화합니다. p.dim() > 1 조건은 2차원 이상의 텐서들만 초기화 대상으로 선택합니다. Xavier 초기화는 파라미터가 적절히 초기화되어 학습이 잘 진행될 수 있도록 돕습니다.
드디어 끝났다.
트레이닝 코드는 구태여 설명하지 않을테니 참고만 하자.
Training
class Batch:
"Object for holding a batch of data with mask during training."
def __init__(self, src, trg=None, pad=0):
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if trg is not None:
self.trg = trg[:, :-1]
self.trg_y = trg[:, 1:]
self.trg_mask = \
self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
return tgt_mask
def run_epoch(data_iter, model, loss_compute):
"Standard Training and Logging Function"
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
for i, batch in enumerate(data_iter):
out = model.forward(batch.src, batch.trg,
batch.src_mask, batch.trg_mask)
loss = loss_compute(out, batch.trg_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 50 == 1:
elapsed = time.time() - start
print("Epoch Step: %d Loss: %f Tokens per Sec: %f" %
(i, loss / batch.ntokens, tokens / elapsed))
start = time.time()
tokens = 0
return total_loss / total_tokensglobal max_src_in_batch, max_tgt_in_batch
def batch_size_fn(new, count, sofar):
"Keep augmenting batch and calculate total number of tokens + padding."
global max_src_in_batch, max_tgt_in_batch
if count == 1:
max_src_in_batch = 0
max_tgt_in_batch = 0
max_src_in_batch = max(max_src_in_batch, len(new.src))
max_tgt_in_batch = max(max_tgt_in_batch, len(new.trg) + 2)
src_elements = count * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max(src_elements, tgt_elements)
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"Implement `lrate` above"
if step is None:
step = self._step
return self.factor * \
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
# Three settings of the lrate hyperparameters.
opts = [NoamOpt(512, 1, 4000, None),
NoamOpt(512, 1, 8000, None),
NoamOpt(256, 1, 4000, None)]
plt.plot(np.arange(1, 20000), [[opt.rate(i) for opt in opts] for i in range(1, 20000)])
plt.legend(["512:4000", "512:8000", "256:4000"])
None
class LabelSmoothing(nn.Module):
"Implement label smoothing."
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(size_average=False)
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))# Example of label smoothing.
crit = LabelSmoothing(5, 0, 0.4)
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0]])
v = crit(Variable(predict.log()),
Variable(torch.LongTensor([2, 1, 0])))
# Show the target distributions expected by the system.
plt.imshow(crit.true_dist)
None
마치며
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Transformer(num_tokens=4,
dim_model=8,
num_heads=2,
num_encoder_layers=3,
num_decoder_layers=3,
dropout_p=0.1).to(device)
opt = torch.optim.SGD(model.parameters(), lr=0.01)
loss_fn = nn.CrossEntropyLoss()굉장히 길고도 긴 포스팅이었다. 자세하게 쓰려고 하다보니 그런 것도 같다.
지금 보면 굉장히 긴 코드들이 바로 위의 코드와 같이 하나의 객체만 선언하면 된다는 점이 Pytorch와 같은 프레임워크의 좋은 점 같기도 하다.(직접 구현하려면 죽어나는..)
Transformer 모델은 어려워보이지만, 직접 구현된 걸 하나하나씩 자세히 뜯어 본다면 생각보다 이해하기 쉬운 모델이다.
그러니 가져다 쓰더라도 일단 이해는 하고 쓰자. 왜냐하면 Mamba 아키텍처로 나아가려면 어찌되었건 그 이전의 것들을 아는 것도 중요하다. 언젠가 Attention 구조가 또 다른 분야에 쓰일 지도 모르는 일이니.
이상으로 3탄 포스팅을 마친다.
reference :
Pytorch Transformer 모델 제작자 : https://nlp.seas.harvard.edu/2018/04/03/attention.html