
티스토리 뷰
지난 글과 이어지는 글이다.
기본적으로 텍스트 데이터를 다루는 만큼, 정말 준비를 단단히 해왔다.
Task의 목표는 긴급도를 상/중/하로 나누는 것.
영어 텍스트 라벨링은 메타데이터가 있었지만, 해당 기준에 대한 건 없었기에 일단은 정하고 가야 했다.
그래서 메타데이터에서 death와 potential_death, false alarm, descrition으로 일차로 나누어보기로 결정.
처음 만들어본 코드는 이랬다.
import pandas as pd
# CSV 파일 읽기
file_path = '/kaggle/input/911-recordings/911_recordings/911_metadata.csv'
data = pd.read_csv(file_path)
def classify_emergency(row):
description = row['description']
deaths = row['deaths']
potential_death = row['potential_death']
if pd.notna(deaths) and deaths > 0:
return 2
high_priority_keywords = ["robbery", "violence", "fire", "danger", "emergency", "death"]
medium_priority_keywords = ["suspicious", "loud", "noise", "unease", "conflict", "accident", "injury"]
low_priority_keywords = ["inquiry", "complaint", "general"]
if pd.notna(potential_death) and potential_death > 0:
return 1
if pd.isna(description):
return 0
description_lower = description.lower()
for word in high_priority_keywords:
if word in description_lower:
return 2
for word in medium_priority_keywords:
if word in description_lower:
return 1
return 0
# 긴급도 분류
data['emergence'] = data.apply(classify_emergency, axis=1)
# 분류된 데이터 확인
print(data.head())
# CSV 파일 업데이트
output_file_path = '911_emergency_classified_combined2.csv'
data.to_csv(output_file_path, index=False)
Bert 모델도 좋지만, 일단은 베이스라인을 세우기 위해서, MLP 모델로 Classification을 수행하기로 했다.
descrition(요약본)을 텍스트로 넣고, 일반으로 돌린 결과는 0.77.
이걸 베이스라인으로 잡고 Bert 모델을 돌렸으나, large 모델들은 작은 GPU에서 안돌아가기에 한계가 왔나 싶었다.
텍스트 데이터 증강과 max_length의 상관관계를 증명하다
하루 종일 삽질하다가, max_length에 관한 논문을 읽었고, 텍스트 데이터 증강에 대한 논문을 읽었다.(정말 유명한 2019년도 논문 -"Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks")
또한 특수 분야에서는 분류 종류가 늘어날 수록 오히려 텍스트 데이터를 더 잘 분류한다는 논문도 있었다.
그 후에 바로 코드로 적용해보기로 했다.
import random
from nltk.corpus import wordnet
import nltk
import os
from datasets import Dataset, concatenate_datasets
# 시드 값 설정
random.seed(42) # 예시로 42를 시드 값으로 설정
nltk_data_path = os.path.expanduser('/kaggle/working/')
if not os.path.exists(nltk_data_path):
os.makedirs(nltk_data_path)
nltk.data.path.append(nltk_data_path)
# WordNet 데이터 다운로드
nltk.download('wordnet', download_dir=nltk_data_path)
nltk.download('omw-1.4', download_dir=nltk_data_path)
def get_synonyms(word):
synonyms = set()
for syn in wordnet.synsets(word):
for lemma in syn.lemmas():
synonyms.add(lemma.name())
if word in synonyms:
synonyms.remove(word)
return list(synonyms)
def synonym_replacement(sentence, n):
words = sentence.split()
random_word_list = list(set([word for word in words if get_synonyms(word)]))
random.shuffle(random_word_list)
num_replaced = 0
for random_word in random_word_list:
synonyms = get_synonyms(random_word)
if len(synonyms) >= 1:
synonym = random.choice(synonyms)
words = [synonym if word == random_word else word for word in words]
num_replaced += 1
if num_replaced >= n:
break
return ' '.join(words)
augmented_texts = [synonym_replacement(text, 1) for text in dataset["text"]]
augmented_labels = dataset["label"]
# 증강된 데이터를 원본 데이터에 추가
augmented_dataset = Dataset.from_dict({"text": augmented_texts, "label": augmented_labels})
full_dataset = concatenate_datasets([dataset, augmented_dataset])
영어로 된 텍스트 데이터기 때문에 konlpy가 아닌 nltk를 써서 동의어를 랜덤으로 처리했다.
해당 데이터셋은 기본 데이터셋에 합쳐져 증강된다.
import pandas as pd
# CSV 파일 읽기
file_path = 'output_csv_file (3).csv'
data = pd.read_csv(file_path)
def classify_emergency(row):
description = row['description']
deaths = row['deaths']
potential_death = row['potential_death']
# 최상 긴급도 (3)
if pd.notna(deaths) and deaths > 0:
return 3
if pd.notna(description):
description_lower = description.lower()
high_priority_keywords = ["hostage", "explosion"]
for word in high_priority_keywords:
if word in description_lower:
return 3
# 상 긴급도 (2)
if pd.notna(potential_death) and potential_death > 0:
return 2
if pd.notna(description):
description_lower = description.lower()
high_priority_keywords = ["robbery", "violence", "fire", "danger", "emergency", "death"]
for word in high_priority_keywords:
if word in description_lower:
return 2
# 중간 긴급도 (1)
if pd.notna(description):
description_lower = description.lower()
medium_priority_keywords = ["suspicious", "loud", "noise", "unease", "conflict", "accident", "injury"]
for word in medium_priority_keywords:
if word in description_lower:
return 1
# 하 긴급도 (0)
if pd.notna(description):
description_lower = description.lower()
low_priority_keywords = ["inquiry", "complaint", "general"]
for word in low_priority_keywords:
if word in description_lower:
return 0
return 0
# 긴급도 분류
data['emergence'] = data.apply(classify_emergency, axis=1)
# 분류된 데이터 확인
print(data.head())
# CSV 파일 업데이트
output_file_path = '911_emergency_classified_combined2.csv'
data.to_csv(output_file_path, index=False)긴급도도 최상~하로 4개로분류해주었다.
결과는? 성공적.
해당 모델들에 대한 accuracy를 정리해보면 이러하다.
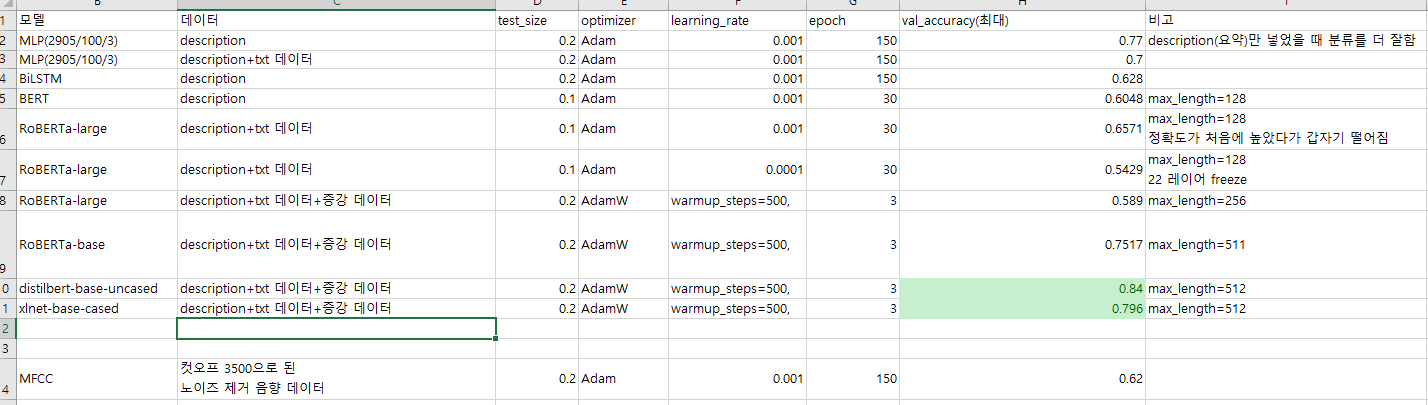
기본적으로 토큰의 max_length가 최대 512정도인데, 당연하게도 해당 토큰의 길이가 많을수록 텍스트 분류 성능은 뛰어났다.
논문은 역시 최고다.
실제 ai hub에서 썼던 것처럼 0.9까지 끌어올리는 게 목표이다. 빅프로젝트 끝까지 열심히 해야겠다.