

티스토리 뷰
STT나 TTS는 제외하고, 단순히 백엔드만의 부하 테스트를 간편하기 위해 Locust로 진행했다.
우리 서비스의 동시 사용자 수는 대략 최대 50~100명으로 예상하고 진행했다.
# locustfile.py
from locust import HttpUser, task, between
import json
import uuid
class SpeechProcessingUser(HttpUser):
# 사용자가 요청 사이에 대기하는 시간 (초 단위)
wait_time = between(1, 3)
@task
def send_speech_text(self):
# 무작위 세션 ID 생성
session_id = str(uuid.uuid4())
# 테스트에 사용할 텍스트 데이터 정의
user_text = "청년기 시절의 기억에 대해 이야기해주세요."
# JSON 형식의 요청 데이터
data = {
"text": user_text,
"session_id": session_id
}
# process_speech 엔드포인트에 POST 요청
self.client.post("/process_speech/", data=json.dumps(data), headers={"Content-Type": "application/json"})
#실행 코드
# locust -f locustfile.py --host=http://localhost:8000
사용한 코드이다.
GPT API 호출을 고려하면 100명에 5명씩 추가한다고 가정했을 때 부하는 다음과 같다.
Django
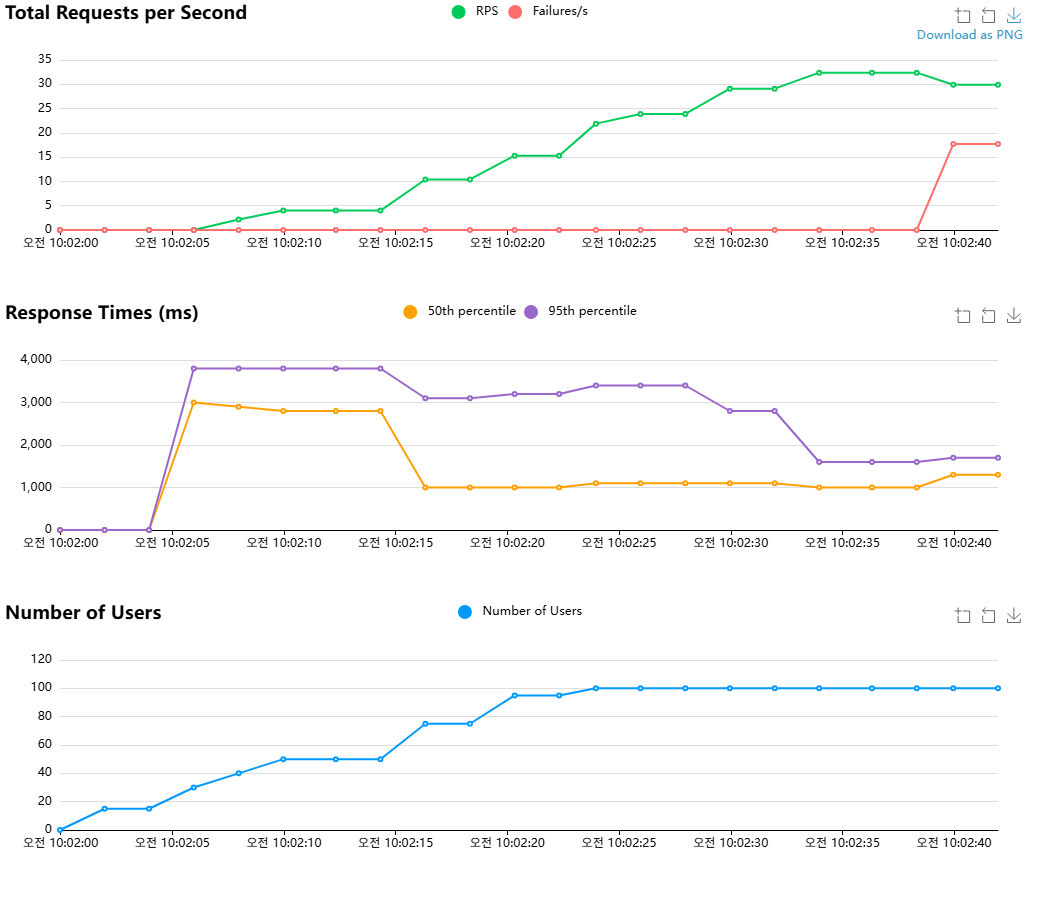
Request Per Second가 Fail하기 직전(GPT API에서 거부하기 직전)인 10:02:40 직전까지만 보면 된다.
처음에는 느리다가 가면 갈수록 1000ms ~1800ms 정도에 수렴하는 걸 볼 수 있다.
그렇다면 50명이면 어떨까?

50명일 때 수치는 900ms ~1400ms 정도로 안정화된 모습이다.
이는 TTS 시간인 1000ms~1500ms까지 합치면 1900ms~2900ms 정도로 예상 사용자 수의 최적 Latency와 일치하기에 적합하다.
FastAPI
똑같이 100명을 해봤다.

?
뭔가 이상하다. FastAPI는 비동기라서 원래 Django보다 더 빨라야 하는거 아닌가?
그래서 워커 수를 16으로 늘리고 10명만 해보았다.

처음엔 부하가 좀 있었지만 가면 갈수록 안정을 찾는 느낌이다.
그래서 이제 50명으로 늘려보았다.

음..역시 정신을 못차린다. 95 percentile이 오락가락하는 상태.
아무래도 뭔가 최적화나 이런게 문제가 되는 거 같다.
그래서 코드를 고쳤다.
import os
import json
import asyncio
from fastapi import FastAPI, Request, HTTPException
from pydantic import BaseModel
from fastapi.responses import JSONResponse
from fastapi.middleware.cors import CORSMiddleware
from langchain.schema import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage
import redis.asyncio as redis
from dotenv import load_dotenv
# Windows 이벤트 루프 설정
if os.name == 'nt':
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
load_dotenv()
# Redis 클라이언트
redis_client = redis.Redis(
host='localhost',
port=6379,
decode_responses=True,
max_connections=50
)
app = FastAPI()
# CORS 설정
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 프롬프트 설정
middle_life_history = '''
{역할:
청년기 시기에 대하여 상대가 이야기 하도록 유도한다.
하고싶었던 일이나 생활들에 대해서 구체적인 질문을 한다.
해당시기의 주요 사건, 의미 있는 관계, 감정 등을 탐색한다.
힘들었던 순간, 재밌었던 순간 등 다양한 기억에 대해서 대화를 나눈다.
한 주제를 너무 깊게 파고들지 말고, 적절하게 다른 주제로 넘어간다.
사용자의 정서 상태를 확인하고 그에 맞는 상담 반응을 제공한다.
질문은 구체적으로 해서 상대가 답변하기 편하도록 한다.
상담기술:
재진술, 구체화, 명료화, 감정 명명, 감정 반영, 타당화를 사용한다. }
'''
prompt = ChatPromptTemplate.from_messages([
("system",
"너는 노인 대상 생애 회고 치료(Life Review Therapy)를 전문으로 하는 심리상담사고 이름은 '봄이'야. "
"너 자신이 상대 어르신의 손녀라고 생각하고, 친근하게 대화해줘. "
"질문을 할 때는 한번에 하나씩만 해야해. "
"노인분과 대화를 나눌건데, 대화를 나누면서 고려해야 할 사항들이 있어. "
"가장 첫 질문은 인사와 안부를 묻고, 인사와 안부에 대한 대화가 있었으면 다음으로 넘어가줘 "
"다음 대화의 역할은 다음과 같아 : {middle_life_history} "
"어르신의 성별은 알 수 없으니, 할머니 혹은 할아버지 어떤 것도 절대 표현하지마."
),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}")
])
# LLM 초기화
llm = ChatOpenAI(model='gpt-4o-mini', temperature=0.2)
class SpeechRequest(BaseModel):
text: str
session_id: str = "default_session"
async def get_chat_history(session_id: str):
"""채팅 기록 가져오기"""
messages_json = await redis_client.get(f"chat_history:{session_id}")
if not messages_json:
return []
messages = json.loads(messages_json)
return [
AIMessage(content=m["content"]) if m["type"] == "ai"
else HumanMessage(content=m["content"])
for m in messages
]
async def save_chat_history(session_id: str, messages):
"""채팅 기록 저장"""
messages_json = json.dumps([
{"type": "ai" if isinstance(m, AIMessage) else "human", "content": m.content}
for m in messages
])
await redis_client.set(f"chat_history:{session_id}", messages_json, ex=3600)
async def get_session_count(session_id: str) -> int:
"""세션 카운트 가져오기"""
count = await redis_client.get(f"count:{session_id}")
return int(count) if count else 0
async def increment_session_count(session_id: str) -> int:
"""세션 카운트 증가"""
return await redis_client.incr(f"count:{session_id}")
async def reset_session_count(session_id: str):
"""세션 카운트 리셋"""
await redis_client.set(f"count:{session_id}", 0)
@app.post("/reset_count")
async def reset_count(request: Request):
data = await request.json()
session_id = data.get("session_id", "default_session")
await reset_session_count(session_id)
return JSONResponse(content={"message": "Count reset to 0"})
@app.post("/process_speech")
async def process_speech(request: SpeechRequest):
try:
user_text = request.text
session_id = request.session_id
if not user_text:
raise HTTPException(status_code=400, detail="No text provided")
# 세션 카운트 처리
count = await get_session_count(session_id)
if count > 5:
user_text = "#### 대화 종료 ####"
await reset_session_count(session_id)
else:
await increment_session_count(session_id)
# 채팅 기록 가져오기
chat_history = await get_chat_history(session_id)
# 새 메시지 추가
new_message = HumanMessage(content=user_text)
messages = chat_history + [new_message]
# 응답 생성
response = await prompt.aformat_messages(
input=user_text,
chat_history=chat_history,
middle_life_history=middle_life_history
)
result = await llm.ainvoke(response)
ai_message = AIMessage(content=result.content)
# 채팅 기록 업데이트
messages.append(ai_message)
await save_chat_history(session_id, messages)
return JSONResponse(content={"response": result.content})
except Exception as e:
print(f"Process speech error: {str(e)}")
raise HTTPException(status_code=500, detail=f"An error occurred: {str(e)}")
@app.on_event("startup")
async def startup_event():
app.state.redis = redis_client
@app.on_event("shutdown")
async def shutdown_event():
await app.state.redis.close()
if __name__ == "__main__":
import uvicorn
uvicorn.run(
"main:app",
host="0.0.0.0",
port=8000,
workers=1,
limit_concurrency=500,
timeout_keep_alive=30,
log_level="info"
)
그 후 100명 부하테스트

장고와 비교해보면, Latency가 거의 비슷한 걸 볼 수 있다.
즉, 작은 규모의 서비스 (50명~100명) 수준에서는 장고도 충분히 서비스 할만 하다.
+번외(1000명 부하테스트) - 50명씩 증가
Django

FastAPI

Django는 Failiure가 거의 없는 대신, Response Time도 비례적으로 증가한다.
반면 FastAPI는 비동기적이라 최대 RPS가 많이 늘어나고, Failiure가 더 많아진다(API를 불러오는 횟수가 많아지기 때문도 있다. 위의 코드에서 Redis의 연결한계를 50으로 설정해놨기 때문)
사실 연결한계를 1000으로 늘려도 결과는 마찬가지이다. ChatGPT API 자체가 분당 20만 Request밖에 못 불러와서 그렇다.
즉, API 수의 Calling 횟수가 정해져 있다면 비동기는 오히려 독이 될 수 있다. 이 부분에 대해서는 API 키를 실시간 교체하거나 API 로드 밸런싱같은 방법을 찾아봐야 할 듯 하다.

그런 점에서 한계는 limit_concurrency=50 정도로 걸어 최대한의 속도를 볼 수 밖에 없을 것이다.

최대 유저수는 600, 50 percentile은 3000ms 정도, 최대 RPS는 33 정도 되시겠다.
뭐든지 장단점이 있는 것이다. 즉, ChatGPT와 같은 Rate Limit 서비스에서는 Django가 사용자가 많을수록 느리지만 안정적인 AI 서비스에 더 적합하다.
이번 실험으로 확실히 알 수 있게 되었다.