
티스토리 뷰
주제
- 미세먼지 농도 예측 머신러닝 모델링
목표
- 탐색적 데이터 분석 복습
- 데이터 전처리 과정 복습
- 머신러닝 모델링 과정 복습
- 머신러닝 모델 평가
프로젝트 내 역할
- 개인 프로젝트
- 다만, ppt에서는 피처 요약표와 모델링 지표 등을 담당
1. 데이터 분석
1.1 구성
- air_2022, air_2023
- 미세먼지 및 오염물질(SO2, CO, O3, NO2, PM25, PM10) 정보
- weather_2022, weather_2023
- 날씨 정보(기온, 강수량, 풍속, 풍향, 습도, 시정 등)
1.2 분석
가장 먼저 피처 요약표 분석

- 명목형에서 고유값이 1인 것들은 타겟 예측력이 없으므로 제거할 생각을 하고 들어간다.
- 연속형이어도 결측값 개수가 5000개보다 많고, 의미 없는 변수(QC값)이라 생각되면 drop해주었다.
2. 데이터 전처리
2.0 데이터 결합
air_data와 weather_data를 년도별로 결합해줘야 한다.
전년도의 데이터로, 후년도의 데이터를 예측할 것이므로, 각각 train과 test가 된다.
그걸 위해 time 컬럼을 생성한다.
2.1 time 컬럼 생성
측정 일시를 통해 time 컬럼을 생성하고, 후에 year은 없애고 month, day,time만 가져온다.
air_22['time'] = pd.to_datetime(air_22['측정일시']-1, format='%Y%m%d%H')
#데이터의 시간 범위가 다르기 때문에, 1~24시를 0~23시로 바꿔준다.
weather_22['time'] = pd.to_datetime(weather_22['일시'])
후에 merge를 한다.
df_all=pd.merge(df1,df2, on='time',how='inner')
2.2 결측치 처리
df22 = df_22.loc[:, df_22.isna().sum() <= 5000]
절반 넘게 없다면 의미가 없으므로 5000을 기준으로 제거
columns =['SO2','CO','NO2','PM10','PM25','O3',]
for column in columns:
df22[column] = df22[column].fillna(method='ffill')
시계열 데이터이므로, 결측 값 중 한 시간 전의 값으로 채워도 충분히 의미 있는 값들이다.
그렇게 채우고 나니, 결측치가 얼마 남지 않았고, 고유값이 1인 것들을 drop해주었다.
df23= df23.dropna(subset=['일조(hr)', '일조 QC플래그', '일사(MJ/m2)', '일사 QC플래그', '전운량(10분위)', '중하층운량(10분위)', '운형(운형약어)', '최저운고(100m )'], how='any')
#결측치가 1개인 값들 삭제
df_23 = df23.loc[:, df23.isna().sum() == 0] #0인 결측치인 녀석들만 선택
#범주형 데이터 중 살리기엔 유의미한 것이 없어서 제거
2.3 고유값 1인 것들 drop
cols_to_drop = df22_co.nunique()[df22_co.nunique() == 1].index #만약 고유값이 1인 녀석들을 삭제하고 싶다면
# 해당 열들을 삭제
df_22= df22_co.drop(cols_to_drop, axis=1)2.4 타깃값 만들기
타깃값은 1시간 뒤의 pm10
shift 연산을 하고, 결측값은 rolling으로 채워준다.
df22_co['PM10_shift']=df22_co['PM10'].shift(24) #일단 shift
rolling_mean_22 = df22_co['PM10'].rolling(window=3, min_periods=1).mean() #3개를 묶어서 rolling
df22_co['PM10_shift'] = df22_co['PM10_shift'].fillna(rolling_mean_22) #그 값으로 na를 채운다.2.5 원 핫 인코딩 및 robust 스케일링
범주형 변수가 하나만 있었으므로 원 핫 인코딩을 해주었다.
시계열 데이터는 특히나 이상치에 민감하므로 robust 스케일링을 통해 줄였다.
3. 머신러닝 결과
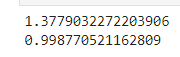
linearRegresson에서 1이 나왔다. 잘못 본줄 알았지만, 솔직히 예상이 가는 바였다.
당연하게도 시계열 데이터이고, 전값을 넣었으니 타겟값과 종속성이 있어서 이렇게 나올 수 밖에 없었다.


pm10을 못 뺀게 아쉬워서 그냥 lightGBM으로 다른 피처 중요도라도 구해보았다.
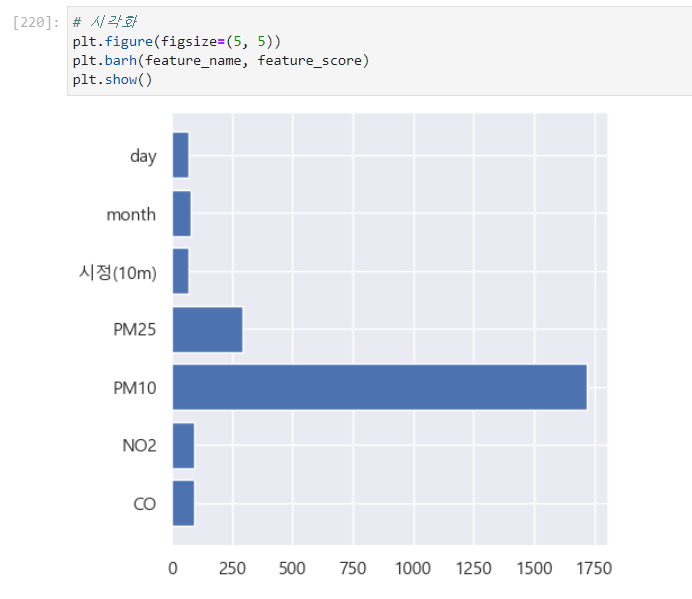
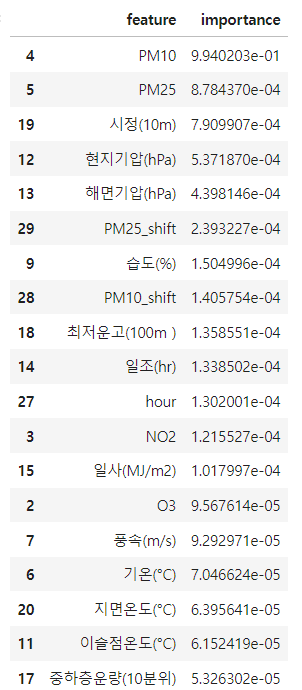
미세먼지 둘을 제외하고는 시정이나 no2,co, 기온, 기압 등이 확실히 영향을 끼치는 걸 알 수 있다.
배운 점과 인사이트
시간이 더 많았으면 PM10을 제거하고 했을 것이다.
하지만 x_test에 대한 모델 예측 결과는 잘 나와서 그러기에도 애매했다.
이미 알고 있는 걸 시간 안에 활용하려면 확실히 전처리 간소화를 위한 템플릿이 중요한 거 같다.
실무에서는 훨씬 더 그럴 것이다.
앞으로의 루틴을 피처 요약표 -> 상관계수로 한번 만들어야 겠다.
다른 조부터 배운 점
피처 요약표에서 결측값에 대한 비율을 추가.
종속변수를 먼저 제거하고 결론을 내는 게 가장 좋다.