
티스토리 뷰
딥러닝 모델 저장
model1.save('./my_first_save.keras')
모델 불러오기
clear_session()
model3 = keras.models.load_model('./my_first_save.keras')
model3.summary()
모델 가중치 불러오기
model3.get_weights()[0][0][0]
이미지를 저장하기 위한 연결
from google.colab import drive
drive.mount('/content/drive')
!ls
!cd /content/drive/MyDrive/my_data; ls
이미지 불러오기
import glob
from keras.preprocessing import image
files = glob.glob('/content/drive/MyDrive/my_data/my_mnist/*')
files
img = image.load_img(files[0], color_mode='grayscale', target_size=(28,28) )
img = image.img_to_array(img)
plt.imshow(img.reshape(img.shape[0], img.shape[1]), cmap='gray')
plt.show()
AI hub
ai 연구를 위한 곳. 데이터가 엄청나게 많다. 코랩에서도 안 돌아간다.
연구원일 때 써라.
cifar = 5만~6만장
이미지 데이터를 폴더 별로 정리한 상태라면?
from keras.utils import image_dataset_from_directory# idfd_train, idfd_valid = image_dataset_from_directory('/content/drive/MyDrive/my_data/my_mnist2',
# label_mode='categorical',
# color_mode='grayscale',
# image_size=(28,28),
# seed=2024,
# validation_split=0.2,
# subset='both'
# )
idfd_train = image_dataset_from_directory('/content/drive/MyDrive/my_data/my_mnist2',
label_mode='categorical',
color_mode='grayscale',
image_size=(28,28),
)idfd_train을 활용한다.
clear_session()
model5 = keras.models.load_model('./model1.keras')
# model5.summary()
model5.fit(idfd_train,
# validation_data=idfd_valid,
epochs=100, verbose=1)
전이학습(transfer learning)
그를 위해 우리는 모델이 일반적인 상황에서 잘 동작하기를 기대한다(Robust-강건성)이 좋기를 기대한다.
잘 만든 모델(pretrained model)을 가져다가, 레이어를 추가로 붙여서 사용하거나 혹은 중간의 가중치를 초기화해서 사용할 수 있다.
이를 전이학습이라고 한다.
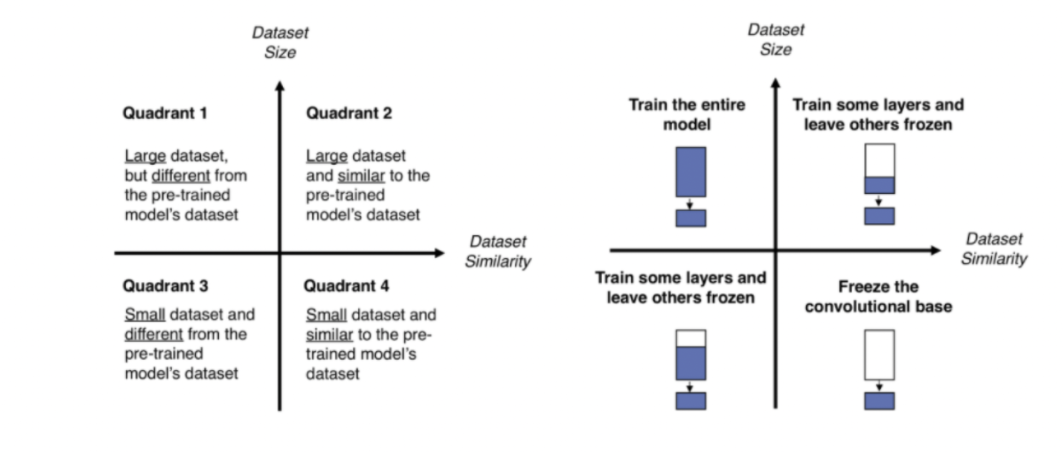
1 사분면 : 전체 재학습
큰 데이터셋이지만, pre-trained model의 데이터셋이랑 다를 경우
전체 모델을 재학습한다.
2 사분면: 조금의 레이어만 재학습 - 파인 튜닝
큰 데이터셋이고, pre-trained model의 데이터셋이랑 비슷할 경우
3 사분면 : 절반 이상의 레이어 재학습 -파인 튜닝
작은 데이터셋이고, pred-trained model의 데이터셋이랑 다를 경우
4 사분면 : 베이스는 유지하고, 레이어 추가 - 사전학습
작은 데이터셋이고, pre-trained model의 데이터셋이랑 비슷할 경우
경우에 따라서 전이학습을 활용하는 용도가 다르다.
aumentation의 한계점
- 원본과 확연히 다른 새로운 특징은 만들어 낼 수 없다.
- 애초에 적절한 데이터인지를 모른다.(양과 질을 모두 충족하는)
소규모 연구자가 거대한 모델을 운용하기에는 너무 힘들다.
그래서 조금만 고쳐 사용하는 걸 목표로 사용한 게 근간이다.
여기서는 4 사분면의 케이스만 설명한다.
vgg 모델을 가져온다.
vgg_model = VGG16(include_top=True, # VGG16 모델의 아웃풋 레이어까지 전부 불러오기
weights='imagenet', # ImageNet 데이터를 기반으로 학습된 가중치 불러오기
input_shape=(224,224,3) # 모델에 들어가는 데이터의 형태
)
plot 모델을 사용하면 해당 레이어들이 어떻게 되어 있는지 볼 수 있다.
from keras.utils import plot_model
plot_model(vgg_model, show_shapes=True, show_layer_names=True)
img1 폴더에서, files 변수에 있는 모든 이미지 데이터를 불러온다.
import glob
from keras.preprocessing import image
files = glob.glob('/content/drive/MyDrive/my_data/img1/*')
files
img = image.load_img(files[-1], color_mode='rgb', target_size = (224,224) )
img = image.img_to_array(img)
img = img.reshape((-1,224,224,3))
print(f'preprocess 전: 최대값={np.max(img)}, 최소값={np.min(img)}')
img = preprocess_input(img)
print(f'preprocess 후: 최대값={np.max(img)}, 최소값={np.min(img)}')
features = vgg_model.predict(img)
print(decode_predictions(features, top=3))
plt.imshow(image.load_img(files[-1]))
plt.show()
files에 있는 path에 대해서, 각 이미지를 preprocessing 한다.
images = []
for path in files :
img = image.load_img(path, color_mode='rgb', target_size=(224,224) )
img = image.img_to_array(img)
img = preprocess_input(img)
images.append(img)
images = np.array(images)
그리고 나서 input으로 만든다.
features = vgg_model.predict(images)
predictions = decode_predictions(features, top=3)
for i in range(images.shape[0]) :
print(predictions[i])
plt.imshow(image.load_img(files[i]))
plt.show()
불러온 모델 자체의 prediction으로도 웬만한 결과를 낼 수 있다.
가중치 고치기
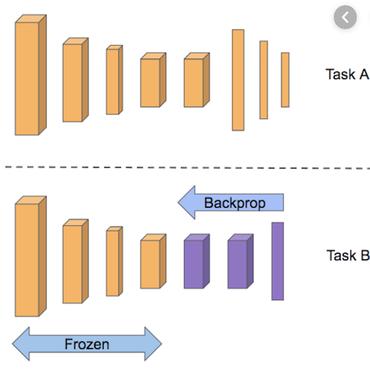
backprop에 해당하는 과정이다.
https://www.tensorflow.org/api_docs/python/tf/keras/applications
해당 링크에서 keras에서 쓸 수 있는 pretrained learning 모델들을 볼 수 있다.
ConvNeXtBase(...): Instantiates the ConvNeXtBase architecture.
ConvNeXtLarge(...): Instantiates the ConvNeXtLarge architecture.
ConvNeXtSmall(...): Instantiates the ConvNeXtSmall architecture.
ConvNeXtTiny(...): Instantiates the ConvNeXtTiny architecture.
ConvNeXtXLarge(...): Instantiates the ConvNeXtXLarge architecture.
DenseNet121(...): Instantiates the Densenet121 architecture.
DenseNet169(...): Instantiates the Densenet169 architecture.
DenseNet201(...): Instantiates the Densenet201 architecture.
EfficientNetB0(...): Instantiates the EfficientNetB0 architecture.
EfficientNetB1(...): Instantiates the EfficientNetB1 architecture.
EfficientNetB2(...): Instantiates the EfficientNetB2 architecture.
EfficientNetB3(...): Instantiates the EfficientNetB3 architecture.
EfficientNetB4(...): Instantiates the EfficientNetB4 architecture.
EfficientNetB5(...): Instantiates the EfficientNetB5 architecture.
EfficientNetB6(...): Instantiates the EfficientNetB6 architecture.
EfficientNetB7(...): Instantiates the EfficientNetB7 architecture.
EfficientNetV2B0(...): Instantiates the EfficientNetV2B0 architecture.
EfficientNetV2B1(...): Instantiates the EfficientNetV2B1 architecture.
EfficientNetV2B2(...): Instantiates the EfficientNetV2B2 architecture.
EfficientNetV2B3(...): Instantiates the EfficientNetV2B3 architecture.
EfficientNetV2L(...): Instantiates the EfficientNetV2L architecture.
EfficientNetV2M(...): Instantiates the EfficientNetV2M architecture.
EfficientNetV2S(...): Instantiates the EfficientNetV2S architecture.
InceptionResNetV2(...): Instantiates the Inception-ResNet v2 architecture.
InceptionV3(...): Instantiates the Inception v3 architecture.
MobileNet(...): Instantiates the MobileNet architecture.
MobileNetV2(...): Instantiates the MobileNetV2 architecture.
MobileNetV3Large(...): Instantiates the MobileNetV3Large architecture.
MobileNetV3Small(...): Instantiates the MobileNetV3Small architecture.
NASNetLarge(...): Instantiates a NASNet model in ImageNet mode.
NASNetMobile(...): Instantiates a Mobile NASNet model in ImageNet mode.
ResNet101(...): Instantiates the ResNet101 architecture.
ResNet101V2(...): Instantiates the ResNet101V2 architecture.
ResNet152(...): Instantiates the ResNet152 architecture.
ResNet152V2(...): Instantiates the ResNet152V2 architecture.
ResNet50(...): Instantiates the ResNet50 architecture.
ResNet50V2(...): Instantiates the ResNet50V2 architecture.
VGG16(...): Instantiates the VGG16 model.
VGG19(...): Instantiates the VGG19 model.
Xception(...): Instantiates the Xception architecture.
실제 코드
inception 모델을 쓴다.
import keras
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3 import preprocess_input
from keras.applications.inception_v3 import decode_predictions
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
from keras.preprocessing import image
from keras.utils import to_categorical
from keras.layers import GlobalAveragePooling2D, Dense
from sklearn.model_selection import train_test_split
import random
import numpy as np
import matplotlib.pyplot as plt
import glob
colab을 기준으로 설명한다.
from google.colab import drive
drive.mount('/content/drive')
!cd /content/drive/MyDrive/my_data/; ls #폴더에 들어 있는 파일 확인
!cd /content/drive/MyDrive/my_data/transfer; ls #폴더에 들어 있는 파일들 확인
files = glob.glob('/content/drive/MyDrive/my_data/transfer/*/*')
files #파일 경로 할당하기
files[-1].split('/')[-2] #파일 대분류 확인하기(폴더 이름 확인하기)
name_cnt = {}
for x in files :
name_cnt[x.split('/')[-2]] = name_cnt.get(x.split('/')[-2], 0) + 1
#대분류 이름이 각각 몇 개 있는지 확인하기
name_cnt
{'모닝': 10, 'ev6': 9, 'k5': 10}
그리고 나서 각 레이블에 대해 레이블 인코딩을 해준다.
i = 0
names = {}
for key in name_cnt :
names[key] = i # names_cnt의 key값에 새로운 값 부여
i += 1 # 클래스 수만큼 i값 증가
names
{'모닝': 0, 'ev6': 1, 'k5': 2}
그렇게 받은 이미지를 array로 바꿔준다.
images = []
labels = []
for path in files:
img = image.load_img(path, target_size=(299,299) )
img = image.img_to_array(img)
images.append(img)
labels.append(names[path.split('/')[-2]]) #names에 해당하는 이름에 해당하는 0,1,2를 넣는다.
plt.imshow(image.load_img(path))
plt.show()
images_arr = np.array(images)
labels_arr = np.array(labels) #array로 만든다.
print(images_arr.shape)
print(labels_arr.shape)
print(labels_arr)
label_v = len(np.unique(labels_arr))
label_v
> [0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2] = labels_arr
3 -> 이게 클래스의 수
### 라벨링
y = to_categorical(labels, label_v) #그래서 labels를 label_v로 라벨링한다.
print(y[:3])
y.shape
>[[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]]
(29, 3)이렇게 되면 각 y(타겟) 이미지가 라벨링이 된 것이다.
Dataset split
각 이미지 그룹별 분할을 위해서는 코드가 복잡하다.
name_cnt.values()
>dict_values([10, 9, 10])
각 values의 숫자가 있다.
temp = []
init_v = 0
for v in name_cnt.values() : #10이 v로 들었갔다면 10만큼 반복
temp.append( (images[init_v:init_v+v], y[init_v:init_v+v]) ) #temp에 0부터 1이 들어간다.
init_v += v #그리고 나서 각 init_v는 v를 더해준다.
0:1~1:2~2:3...이런 순으로 반복
for i in range(len(temp)) :
x_to_array = np.array(temp[i][0]) #첫번쨰는 image
y_to_array = np.array(temp[i][1]) #두번쨰는 y
train_x, test_x, train_y, test_y =\
train_test_split(x_to_array, y_to_array, test_size=0.2, random_state=2024) #y,x에 대해서 image를 split 한다.
train_x, valid_x, train_y, valid_y =\
train_test_split(train_x, train_y, test_size=0.2, random_state=2024)
if i==0 :
first_tr_x, first_va_x, first_te_x = train_x.copy(), valid_x.copy(), test_x.copy() #i=0이라면 각 copy를 만든다.
first_tr_y, first_va_y, first_te_y = train_y.copy(), valid_y.copy(), test_y.copy()
elif i==1 :
new_tr_x, new_tr_y = np.vstack((first_tr_x, train_x)), np.vstack((first_tr_y, train_y))
new_va_x, new_va_y = np.vstack((first_va_x, valid_x)), np.vstack((first_va_y, valid_y)) #i=1이라면 첫번째와 stack
new_te_x, new_te_y = np.vstack((first_te_x, test_x)), np.vstack((first_te_y, test_y))
else :
new_tr_x, new_tr_y = np.vstack((new_tr_x, train_x)), np.vstack((new_tr_y, train_y)) #아니라면 다시 스택을 쌓는다.
new_va_x, new_va_y = np.vstack((new_va_x, valid_x)), np.vstack((new_va_y, valid_y))
new_te_x, new_te_y = np.vstack((new_te_x, test_x)), np.vstack((new_te_y, test_y))
new_tr_x.shape, new_tr_y.shape, new_va_x.shape, new_va_y.shape, new_te_x.shape, new_te_y.shape
>((17, 299, 299, 3),
(17, 3),
(6, 299, 299, 3),
(6, 3),
(6, 299, 299, 3),
(6, 3))
x와 y, val x와 y, test x와 y가 나뉘어졌다.
# 전처리 하지 않은 파일 따로 시각화 해두기
train_xv, valid_xv, test_xv = train_x.copy(), valid_x.copy(), test_x.copy()
데이터 프로세싱
train 데이터에 대해서는 스케일링을 해줘야 한다.
new_tr_x.max(), new_tr_x.min()
>(255.0, 0.0)
new_tr_x = preprocess_input(new_tr_x) #모델에서 제공하는 프리프로세싱
new_va_x = preprocess_input(new_va_x)
new_te_x = preprocess_input(new_te_x)
new_tr_x.max(), new_tr_x.min()
>(1.0, -1.0)
ImageNet 불러오기
https://image-net.org/challenges/LSVRC/2014/browse-synsets
이미지 넷 대회의 해당 클래스
keras.backend.clear_session()
base_model = InceptionV3(weights='imagenet', # ImageNet 데이터를 기반으로 미리 학습된 가중치 불러오기
include_top=False, # InceptionV3 모델의 아웃풋 레이어는 제외하고 불러오기
input_shape= (299,299,3)) # 입력 데이터의 형태
new_output = GlobalAveragePooling2D()(base_model.output)
new_output = Dense(3, # class 3개 클래스 개수만큼 진행한다.
activation = 'softmax')(new_output)
model = keras.models.Model(base_model.inputs, new_output)
model.summary()사전 학습 모델의 output을 GlobalAveragePolling으로 불러오고, dense를 3으로 잡아주었다.
GolbalAveragePooling은 차원을 엄청나게 줄여준다.
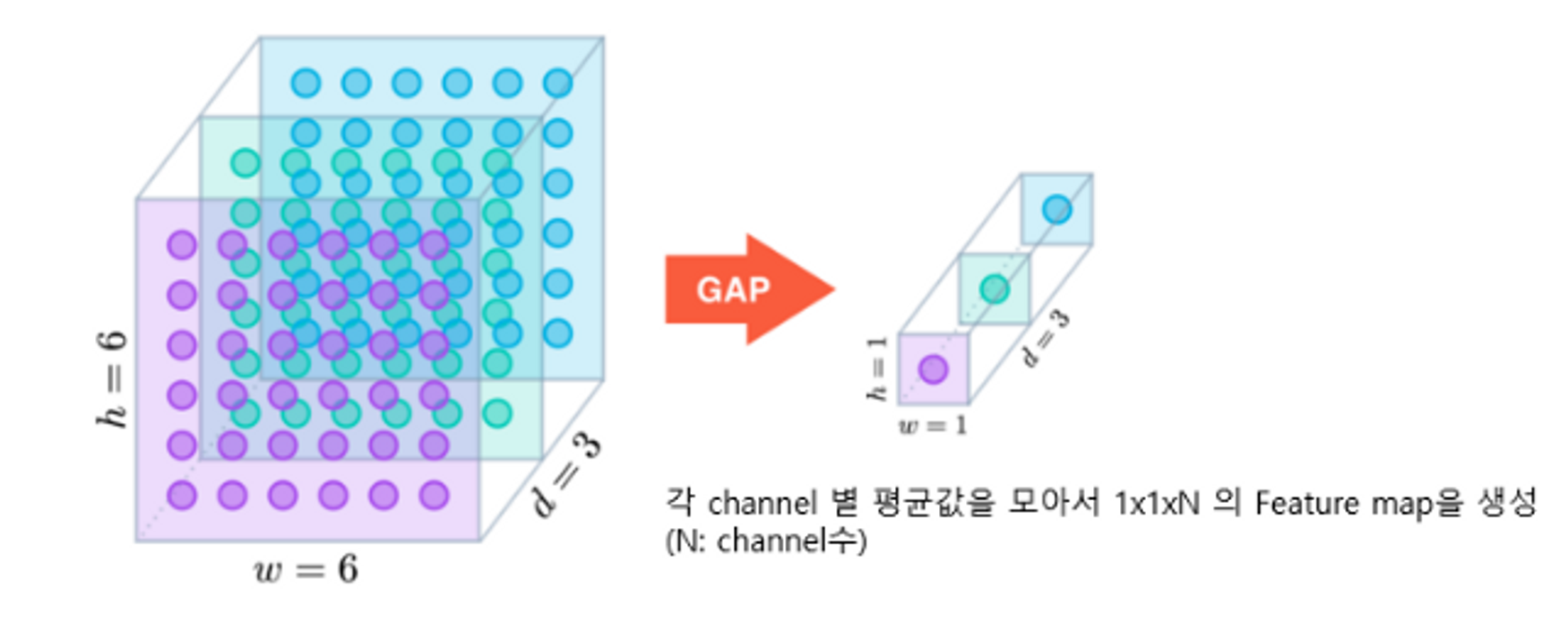
각 채널마다 평균값을 모아서 1*1*n의 feature map으로 바꿔준다.
- 4x4x512를 flatten하면 8192개. feature map의 개수를 128개로만 잡아줘도 8192*128 = 1,048,576개의 weight
- 4x4x512→GlobalAverage를 사용하여 1x1x512로 만든다.
- Dense Layer에 입력 시 512*128 = 65536개의 weight
- flatten 사용보다 파라미터가 확 줄어든다.
from keras.utils import plot_model
plot_model(model, show_shapes=True, show_layer_names=True)
print(f'모델의 레이어 수 : {len(model.layers)}')
plot 모델 및 레이어를 확인할 수 있다.
파인 튜닝
모델의 가중치를 그대로 사용할 레이어와, 추가 학습할 레이어를 선택한다.
model.layers
for idx, layer in enumerate(model.layers) :
if idx < 213 :
layer.trainable = False
else :
layer.trainable = True
for layer in model.layers:
print(layer.name, layer.trainable) #레이어 보기
레이어의 개수를 선택해서 layer.trainable에 저장해놓는다.
여기서는 213 레이어 후부터 다시 학습하는 걸로 선택되었다.
# 처음부터 학습시키는 것도 아니고,
# 마지막 100개의 레이어만 튜닝 할 것이므로 learning rate를 조금 크게 잡아본다.
model.compile(loss='categorical_crossentropy', metrics=['accuracy'],
optimizer=keras.optimizers.Adam(learning_rate=0.001) )
lr_reduction = ReduceLROnPlateau(monitor='val_loss',
patience=4,
verbose=1,
factor=0.5,
min_lr=0.000001)
es = EarlyStopping(monitor='val_loss',
min_delta=0, # 개선되고 있다고 판단하기 위한 최소 변화량
patience=4, # 개선 없는 epoch 얼마나 기다려 줄거야
verbose=1,
restore_best_weights=True)
lr_reduction은 학습률을 증가시켰다가 감소시키는 방법으로, 동적 학습률 변화를 만든다.
# 데이터를 넣어서 학습시키자!
hist = model.fit(train_x, train_y,
validation_data=(valid_x, valid_y),
epochs=1000, verbose=1,
callbacks=[es, lr_reduction]
)
ResNET
vanishing gradient 문제는 레이어를 지날 때 마다 점점 기울기가 소실되는 것이다.
그래서 원본 x를 처음부터 빼가지고, output 자체를 원본 x에 맞춘다.
한마디로 H(x)가 output이라면, H(x)- x (=F(x), 다른 이름으로는 잔차)가 최소화되도록 하는 것이다.
이렇게 하게 되면 장점이 H(x)가 0이 되더라도 무조건 F(x)(=H(x)-x)의 기울기는 1이 된다.
즉, 기울기 소실이 일어날 수가 없는 환경으로 귀결되므로, 최악의 경우에도 전의 가중치가 다음의 가중치로 전달 될 뿐, 기울기 소실이 일어나지는 않는다.
논문 자체에서는 편미분으로 표현하지만( F'(w,b) ), 역전파 연쇄과정에서 Loss/y * y/w 가 되기 때문에 Loss/y 필요하고 y로 미분하면 미분값이 최소 1은 확보라고 한다.
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, Add
def residual_block(input_tensor, filters):
x = Conv2D(filters, (3, 3), padding='same')(input_tensor)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Add()([x, input_tensor])
x = Activation('relu')(x)
return x
def create_resnet(input_shape, num_classes):
inputs = tf.keras.Input(shape=input_shape)
x = Conv2D(64, (7, 7), strides=(2, 2), padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = residual_block(x, 64)
x = residual_block(x, 64)
x = residual_block(x, 64)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
outputs = tf.keras.layers.Dense(num_classes, activation='softmax')(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
return model
# 예시: 32x32 크기의 이미지에 대한 ResNet 모델 생성
model = create_resnet((32, 32, 3), 10)
핵심은 바로 이 부분이다.
x = Add()([x, input_tensor])
Add 레이어는 케라스(Keras)의 기능 중 하나로, 두 개의 입력 텐서를 요소별(element-wise)로 더하는 역할을 합니다.
- Add 레이어는 두 입력 텐서의 형상(shape)이 동일한지 확인합니다. 만약 다르다면 에러를 발생시킵니다.
- 두 입력 텐서의 요소를 하나씩 더합니다. 즉, 첫 번째 텐서의 첫 번째 요소와 두 번째 텐서의 첫 번째 요소를 더하고, 두 번째 요소들을 더하는 식입니다.
- 요소별 덧셈 결과를 새로운 출력 텐서로 반환합니다.
x = [[1, 2],
[3, 4]]
input_tensor = [[5, 6],
[7, 8]]이라고 가정하면, 요소별 덧셈 연산을 수행한다.
- output[0, 0] = x[0, 0] + input_tensor[0, 0] = 1 + 5 = 6
- output[0, 1] = x[0, 1] + input_tensor[0, 1] = 2 + 6 = 8
- output[1, 0] = x[1, 0] + input_tensor[1, 0] = 3 + 7 = 10
- output[1, 1] = x[1, 1] + input_tensor[1, 1] = 4 + 8 = 12
output = [[6, 8],
[10, 12]]아웃풋은 이렇게 나온다.
이렇게 나온 결과를 activation relu에 통과시키면, 그 결과가 해당 공식의 잔차를 최소화하는 방식이 된다.
즉, x가 0이 되더라도, 무조건 input_tensor 값은 나오므로, input_tensor에 대한 activation은 구할 수 있게 된다.
keras.backend.clear_session()
base_model = ResNet50(weights='imagenet', # ImageNet 데이터를 기반으로 미리 학습된 가중치 불러오기
include_top=False, # Restnet 모델의 아웃풋 레이어는 제외하고 불러오기
input_shape= (32,32,3)
pooling='avg' #global average pooling 2D이다.
) # 입력 데이터의 형태
# new_output = GlobalAveragePooling2D()(base_model.output) #pooling 'avg여서 없어도 된다.
new_output = Dense(10, # class 10개 클래스 개수만큼 진행한다.
activation = 'softmax')(base_model.output)
model = keras.models.Model(base_model.inputs, new_output)
model.summary()