
티스토리 뷰
[에이블스쿨] 31일차 - 시각지능 딥러닝(Object Detection, mAP, Yolov8,Roboflow)
sikaro 2024. 4. 4. 17:05여태까지는 이미지 분류를 진행했다.
MNIST
- Fashion MNIST
- CIFAR-10/100
- Caltech-101/256
- ImageNet
- ImageNette / ImageWoof
이제는 object Detection을 다룬다.
단순히 분류 뿐만 아니라, 사물이 어느 위치에 있는지, 그리고 어떤 곳에 있는지를 다룬다.
- PASCAL VOC
- MS COCO(아주 유명한 데이터셋)
- Open Images
- KITTI (자율주행)
- Argoverse
- Global Wheat
- Objects365
- SKU-110K
- VisDrone (3d ) 드론 데이터셋
- xView
roboflow - object Detection에서 전처리 및 데이터셋 사이트
yolo v8도 쓴다. -> v9이 나왔다.
ultralytics라는 회사가 만든 모델은 논문이 없으나, v9는 논문이 있다.
요새는 oriented Bounding Boxes
DOTA (데이터셋)
object Detection의 한계를 탈출하기 위한 방법
어떤 물건의 각도가 틀어지면 다른 물건이라고 판단할 가능성이 높다.
그래서 object Detection을 확장한 것으로, 각도가 틀어져도 똑같은 물체라고 판단할 수 있도록 한다.
Semantic segmentation
MS COCO-Stuff
- CITYSCAPES
- ADE20K
- CamVid
이것도 object detection에서 확장
박스가 아니라 픽셀 단위로 클래스를 분류한다.
물론 아직까지는 자동차나 사람에 대해서도 개별적인 개채로 보지 않는다.
Instance segmentation =Semantic segmentation+object Detection
사람이나 물건마다 픽셀단위로 구별, 개별적인 개체로도 구별
MS COCO
- CITYSCAPES
- ApolloScape
Pose
Ms coco 데이터셋
인체 움직임에 대해서 감지
Vision and Natural Language
Img to text 같은 데이터셋
MS COCO Captions
- Visual Genome
- Flickr30K
들어가기 전 : object dection의 문제
컴퓨터는 사람이 움직일 때, 프레임의 사진이 바뀌는 것으로 인식한다.
컴퓨터 입장에서는 서로 다른 사진이다. 그래서 사람이 나타났다 사라졌다가 한다.
그래서 세부 테스크로 들어가는 연구를 더 많이 하고 있다.
Yolo의 창시자는
Object detection
multi-classification과, Bounding BOX Regression이 합쳐진 문제이다.
Localization : 단 하나의 object 위치를 Bounding Box로 지정하여 찾는다.
Object Detection : 여러 개의 Object들의 위치를 Bounding Box로 지정하여 찾음
기본 근간 : Bounding Box, Class Classification, Confidence Score
IoU와 NMS는 조금 특수한 것
Precision, Recall,AP, mAP
Annotation
픽셀 단위 차이로 성능이 달라질 수 있으므로, 직접 그려봐야 한다.
Bounding Box
x min,y min, x max, y max
추가로 x center, y center, width, height
좌측 상단에 있는 점과 우측 하단에 있는 점을 이용해서 박스를 만들 수도 있다.
어떤 방식으로 박스를 만드는 지 살펴볼 필요가 있다.
모델이 Object가 있는 위치를 잘 예측한다.
모델이 물체의 크기 자체를 잘 예측한다.
Confidence Score
object가 Bounding Box 안에 있는지, 이에 대한 확신의 정도이다.
Ground-Truth Bounding Box의 Confidence Score = 1 => 실제 모델의 꼭지점을 만들었으므로.
그러므로 모델이 예측하는 Predicted Bounding Box의 Confidence Score는 0~1
1에 가까울 수록 Object가 있다고 판단하는 것이다.
모델에 따라 계산이 조금씩 다르다.
1. 단순히 Object가 있을 확률
2. object가 있을 확률 * IoU
3. object가 특정 클래스일 확률 * IoU
IoU (Intersection Over Union)
Ground-Truth Bounding Box (실제 물체)
Predicted Bounding Box(예측한 박스)
두 박스의 값이 얼마나 겹치는지에 대한 걸 본 것이다.
Area of over lap / Area of Union
쉽게 말하자면 교집합 / 합집
겹치는 부분이 많을 수록, 즉, 1로 갈수록 좋은 예측이다.
초록 색의 정답박스(예측 정답박스)
빨간색의 정답박스(물체의 정답박스)
NMS(Non-Maximum Suppression) 알고리즘
동일 object에 대한 중복 박스를 제거한다
1. 일정 Confidence Score 이하의 Bounding Box 제거 - 일정 Threshold 이하
어떻게 설정하는가에 따라서 boxing 기준이 달라진다.
2. 남은 Bounding Box들을 Confidence Score 순으로 내림차순 정렬
3. 첫 Bounding Box(Confidence Score가 가장 높은!)와의 IoU 값이 일정 이상인 박스들을 제거
ex) 2 박스를 예측했는데, 상대적으로 Confidence가 낮은 박스를 제거한다.
4. Bounding Box가 하나가 될 때까지 반복한다.
IoU가 일정 값 이상이면
같은 Object를 가리키는 것이라고 판단,
상대적으로 Confidence Score가
낮은 Bounding Box를 제거하는 것
Confidence Score Threshold
IoU Threshold 두개는 HyperParameter이다.
Confidence Score Threshold가 높을수록(예측 값이 높은 것만 남길 수록),
IoU Threshold가 낮을수록(겹치는 영역이 적을수록),
중복 박스에 대한 판단이 깐깐해진다.
NMS에서의 IoU Threshold
만약 0.25라고 해보자.
예측 박스 3가지가 있다.(빨간색 예측박스, 초록색 예측박스, 파란색 초록박스)
이 중 빨간색 > 초록색 > 파란색 순으로 Confidence Score가 높다고 하자.(빨간색이 제일 최상위)
사람이란 걸 인지 시킬 때는 위치 정보가 없으므로, 그냥 박스를 여러개 그린다.
IoU Threshold는 빨간색,초록색, 파란색의 겹치는 영역이 0.25이상인 곳이 있다면
똑같은 object를 가르킨다고 판단하여, 초록색, 파란색의 박스는 지워버린다.
그러면 0.1로 내려간다면?
더 많은 박스를 지워버린다.
즉, 조금만 겹쳐도 다 중복이라고 판단하므로 그 기준이 깐깐해진다는 것이다.
Precision, Recall, AP, mAP
TP : 실제 Object를 모델이 Object라 예측 -> 모델이 올바르게 탐지
FP : Object 아닌데 모델이 Object라 예측 -> 모델의 잘못된 탐지
FN : 실제 Object를 모델이 아니라고 예측-> 모델의 잘못된 탐지
TN : Object 아닌데 모델도 아니라고 예측-> 모델이 탐지하지 않음
IoU Threshold 값에 따라서 Precision, Recall 값이 변화한다.
IoU Threshold 값에 따른 변화 -> IoU Threshold 값을 올렸다. (중복되는 박스들을 제거한다)
TP에 대한 기준이 깐깐해진다. -> 깐깐해지므로 진짜 강아지인데도 강아지라고 판단을 못함 -> 강아지의 개수가 줄어든다.
Precision은 올랐다(강아지인 걸 강아지라고 맞췄다).
Recall은 줄어든다. (실제 강아지의 수는 고정이고, 예측한 강아지의 수는 줄어들었다.)
반대로 내리면?
Precision은 줄어든다.(강아지가 아닌 것들도 강아지라고 판단하게 된다)
Recall은 1 (실제 강아지의 수, 맞춘 강아지의 수가 전부 들어간다)
없는 곳도 있다고 판단하는 기준이 많아진다. -> 강아지가 아닌데 강아지라고 판단하는 것들이 많아진다.
TP에 대한 기준이 느슨해져서 그렇다.
Precision - Recall Curve

Precision과 Recall을 모두 감안한 지표
이 아래의 영역을 AP(Average Precision)라고 한다.
AP는 클수록 좋다. 면적이 넓을수록 좋은 것이다. 이는 모델의 객체탐지 정확도에 의해 결정된다.
그런데 Average Precision은 클래스 하나에만 보는 것.
mAP(mean Average Precision은 각 클래스 별 AP를 합산하여 평균을 낸 것이다.
Confidence score Threshold를 낮추면, 감지하는 강아지는 계속 늘어난다.
그러나 그만큼 Precision은 낮아지고, recall은 높게 변화할 확률이 높다.
MS COCO는 mAP[0.5:0.95]로 반영되어 있다.
MS COCO 데이터셋에서 mAP[0.5:0.95]는 IoU(Intersection over Union) 임계값을 0.5부터 0.95까지 0.05 간격으로 변화시키며 계산한 mAP의 평균값을 의미합니다.
- IoU 임계값을 0.5로 하여 mAP를 계산
- IoU 임계값을 0.55로 하여 mAP를 계산
- IoU 임계값을 0.6, 0.65, ..., 0.9, 0.95로 하여 mAP를 각각 계산
- 위에서 구한 9개의 mAP 값을 평균내어 최종 mAP[0.5:0.95] 값을 산출
이렇게 다양한 IoU 임계값에서의 mAP를 평균내는 이유는 특정 IoU 값에 치우치지 않고 모델의 전반적인 성능을 공정하게 평가하기 위함입니다.
결과적으로 mAP[0.5:0.95]는 IoU 0.5 ~ 0.95 범위에서 모델의 전반적인 객체 탐지 능력을 종합적으로 평가하는 지표가 됩니다. 값이 클수록 넓은 IoU 범위에서 높은 성능을 내는 모델이라고 볼 수 있습니다.
박스를 얼마나 잘 맞추는지가 mAP이다.
Annotation
이미지 내 Detection 정보를 별도의 설명 파일로 제공되는 것을 Annotation이라고 한다.
Annotation은 Object의 Bounding Box 위치나 Object 이름 등을 특정 포맷으로 제공한다.
VOC(.xml)
COCO(.json)
ImageNet(.xml)
OpenImages(.csv)
위치, 클래스는 반드시 제공해야 한다.
하나의 데이터 당 kim_1,jpg가 있으면, kim_1.txt 파일이 반드시 있어야 한다.
ultralyrics docs랑 github는 반드시 확인해보자
yolov8 docs
yolo는 깃허브에만 올려놓는다.

파라미터가 작을수록 경량화가 된것.
파라미터가 작음에도 빠르기와 mAP가 강화되었다는 걸 보여주고 싶은 것이다.
papers with code
object dection중에서도
real-time object_detection에 대해서 세부 태스트가 다 나뉘어져있다.
yolo v6가 현재는 제일 높다.
https://paperswithcode.com/task/real-time-object-detection

Yolo v8
기본적으로 전이학습이다.
!pip install ultralytics
from ultralytics import YOLO
model =YOLO() #모델 선언 / 모델 구조 및 가중치를 설정한다.
model.train() #모델 학습 / 학습에 관련된 설정이 가능하다.
model.val() #모델 검증 / 학습된 모델의 성능을 검증한다.
model.predict() #예측값 생성 / 데이터의 예측 결과를 생성한다.
Two-stage는 일단 object localization을 하고, classification을 수행한다.
그러나 yolo와 같은 one-stage는 둘 다 동시에 한다.
yolov8와서 추상화가 되었다.
처음 익히는 입장에서는 좋을 수 있겠지만, 무슨 과정인지 헷갈릴 수 있다.

기본적으로 그냥 yolo()로 모델을 지정해주면, yolov8n이 된다.
Detection 뿐만 아니라, Segmentation, Pose, OBB, Classification에 대한 정보도 있다.

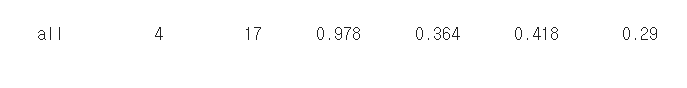
| all | 전체 이미지 수 | 학습에 사용된 이미지의 총 개수 |
| 4 | 객체 수 | 학습 이미지에서 감지된 객체의 총 개수 |
| 17 | 클래스 수 | 학습 모델에서 구분하는 객체 클래스의 총 개수 |
| 0.978 | mAP (Mean Average Precision) | 모델의 정확도를 측정하는 지표, 0~1 사이의 값이며 높을수록 정확도가 높음 |
| 0.364 | precision | 모델이 객체를 정확하게 감지한 비율 |
| 0.418 | recall | 실제 존재하는 모든 객체를 모델이 감지한 비율 |
| 0.29 | F1 score | precision과 recall의 조화 평균 |
- 4: 정확하게 감지된 객체의 개수를 나타냅니다. 이 경우 4개의 객체가 정확하게 감지되었음을 의미합니다.
- 17: 누락된 객체의 개수를 나타냅니다. 이 경우 17개의 객체가 누락되었음을 의미합니다.
- 0.978: 평균 정밀도(mAP)를 나타냅니다. mAP는 모델이 개체를 얼마나 정확하게 감지하는지를 측정하는 지표입니다. 0에서 1 사이의 값이며, 1에 가까울수록 성능이 우수합니다. 이 경우 mAP는 0.978로 매우 높습니다.
- 0.364: 평균 정밀도@0.5 IOU를 나타냅니다. mAP@0.5 IOU는 모델이 개체를 얼마나 정확하게 감지하는지를 측정하는 지표이며, IOU(Intersection over Union)가 0.5 이상인 경우에만 고려됩니다. 이 경우 mAP@0.5 IOU는 0.364입니다.
- 0.418: 평균 정밀도@0.75 IOU를 나타냅니다. mAP@0.75 IOU는 모델이 개체를 얼마나 정확하게 감지하는지를 측정하는 지표이며, IOU(Intersection over Union)가 0.75 이상인 경우에만 고려됩니다. 이 경우 mAP@0.75 IOU는 0.418입니다.
- 0.29: 평균 정밀도@0.95 IOU를 나타냅니다. mAP@0.95 IOU는 모델이 개체를 얼마나 정확하게 감지하는지를 측정하는 지표이며, IOU(Intersection over Union)가 0.95 이상인 경우에만 고려됩니다. 이 경우 mAP@0.95 IOU는 0.29입니다.
engine/trainer: task=detect,
mode=train,
model=yolov8n.pt,
data=coco8.yaml,
epochs=100,
time=None,
patience=100,
batch=16,
imgsz=640, save=True,
save_period=-1, cache=False,
device=None, workers=8,
project=None, name=train,
exist_ok=False, pretrained=True,
optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs/detect/train
train의 기본적인 파라미터들이 있고, data augmentation 등 엄청난 파라미터들이 많다.
model.predict(save=True, save_txt=True)이렇게 하면, 저장하고 나타낸 결과를 보여준다.
txt를 열어보면, box의 위치 정보가 나타난다.
0 0.480416 0.63164 0.23231 0.23131
27 0.375048 k k k...
class 정보, x, y, w, h 순으로 나타내진다.
images 안에 train set validation set을 넣고,
그에 맞는 txt를 같이 넣어야 한다.
Yolo를 사용
- Parameters
- data : 학습시킬 데이터셋의 경로. default 'coco128.yaml'
- epochs : 학습 데이터 전체를 총 몇 번씩 학습시킬 것인지 설정. default 100
- patience : 학습 과정에서 성능 개선이 발생하지 않을 때 몇 epoch 더 지켜볼 것인지 설정. default 50
- batch : 미니 배치의 사이즈 설정. default 16. -1일 경우 자동 설정.
- imgsz : 입력 이미지의 크기. default 640
- save : 학습 과정을 저장할 것인지 설정. default True
- project : 학습 과정이 저장되는 폴더의 이름.
- name : project 내부에 생성되는 폴더의 이름.
- exist_ok : 동일한 이름의 폴더가 있을 때 덮어씌울 것인지 설정. default False
- pretrained : 사전 학습된 모델을 사용할 것인지 설정. default False
- optimizer : 경사 하강법의 세부 방법 설정. default 'auto'
- verbose : 학습 과정을 상세하게 출력할 것인지 설정. default False
- seed : 재현성을 위한 난수 설정
- resume : 마지막 학습부터 다시 학습할 것인지 설정. default False
- freeze : 첫 레이어부터 몇 레이어까지 기존 가중치를 유지할 것인지 설정. default None
1,2,3이 제일 중요하다.
from ultralytics import settings
settings
{'settings_version': '0.0.4',
'datasets_dir': '/content/datasets',
'weights_dir': 'weights',
'runs_dir': 'runs',
'uuid': '569f3ba64b326db489132663f79cd37279811de477381b83ac131e6cdd129cbb',
'sync': True,
'api_key': '',
'openai_api_key': '',
'clearml': True,
'comet': True,
'dvc': True,
'hub': True,
'mlflow': True,
'neptune': True,
'raytune': True,
'tensorboard': True,
'wandb': True}yaml의 데이터셋 다운로드라던가
trainset : 경로, valiset 경로라던가를 설정할 수 있다.
스택 오버플로우에서 끌어다 쓰는 과정에서 오류가 발생할 수 있다.
clearml 부터 wandb 는 결과물을 어디에 공유할 수 있도록 도와주는 것
모델 선언
- 모델의 구조와 해당 구조에 맞게 사전 학습된 가중치를 불러온다.
- Parameters
- model : 모델 구조 또는 모델 구조 + 가중치 설정. task와 맞는 모델을 선택해야 한다.
- task : detect, segment, classify, pose 중 택일
model = YOLO(model='yolov8n.pt', task='detect')파라미터를 넣어서 달리한다.
https://docs.ultralytics.com/ko
무조건 docs를 봐라.
content 폴더에 yolov8n 버전이 추가된다.
Train 파라미터
- Parameters
- data : 학습시킬 데이터셋의 경로. default 'coco128.yaml'
- epochs : 학습 데이터 전체를 총 몇 번씩 학습시킬 것인지 설정. default 100
- patience : 학습 과정에서 성능 개선이 발생하지 않을 때 몇 epoch 더 지켜볼 것인지 설정. default 50
- batch : 미니 배치의 사이즈 설정. default 16. -1일 경우 자동 설정.
- imgsz : 입력 이미지의 크기. default 640
- save : 학습 과정을 저장할 것인지 설정. default True
- project : 학습 과정이 저장되는 폴더의 이름.
- name : project 내부에 생성되는 폴더의 이름.
- exist_ok : 동일한 이름의 폴더가 있을 때 덮어씌울 것인지 설정. default False
- pretrained : 사전 학습된 모델을 사용할 것인지 설정. default False
- optimizer : 경사 하강법의 세부 방법 설정. default 'auto'
- verbose : 학습 과정을 상세하게 출력할 것인지 설정. default False
- seed : 재현성을 위한 난수 설정
- resume : 마지막 학습부터 다시 학습할 것인지 설정. default False
- freeze : 첫 레이어부터 몇 레이어까지 기존 가중치를 유지할 것인지 설정. default None
model.train(data='coco128.yaml',
epochs=10,
patience=5,
save=True,
# project='trained',
# name='trained_model',
exist_ok=False,
pretrained=False,
optimizer='auto',
verbose=False,
seed=2023,
resume=False,
freeze=None
)
레이어를 보면, conv 레이어로 되어 있고,
SPPF, upsample(확대시키는) 레이어도 있는 걸 볼 수 있다.
태초의 object detection을 보면 공부해야 할 것 중 하나이다.
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
16 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
19 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 1 493056 ultralytics.nn.modules.block.C2f [384, 256, 1]
22 [15, 18, 21] 1 897664 ultralytics.nn.modules.head.Detect [80, [64, 128, 256]]
Model summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
head.Detect 레이어도 있다.
옵션을 pretrained=False로 줬는데도 transfer learning을 설정했다.
명령어가 먹히지 않는 경우가 있다.
sgd에서 adamw로 바뀌었다.
128 장 내에 박스 쳐놓은 게 929개 그 후에 precision, recall
all 128 929 0.739 0.627 0.71 0.526
Class Images Instances Box(P R mAP50 mAP50-95)
all 128 929 0.734 0.607 0.7 0.524- Box(P R mAP50 mAP50-95): 이는 모델이 해당 클래스의 객체를 감지하는 정확도를 나타내는 지표입니다.
- P: 정밀도(Precision)를 나타냅니다. 이는 모델이 감지한 객체 중 실제로 해당 클래스의 객체인 비율을 나타냅니다. 0에서 1 사이의 값이며, 1에 가까울수록 정확도가 높습니다. 이 경우 정밀도는 0.734입니다.
- R: 재현율(Recall)을 나타냅니다. 이는 실제로 존재하는 해당 클래스의 객체 중 모델이 감지한 객체의 비율을 나타냅니다. 0에서 1 사이의 값이며, 1에 가까울수록 정확도가 높습니다. 이 경우 재현율은 0.607입니다.
- mAP50: 평균 정밀도(mAP)를 나타냅니다. 이는 IOU(Intersection over Union)가 0.5 이상인 경우에만 고려되는 객체 감지 정확도를 측정하는 지표입니다. 0에서 1 사이의 값이며, 1에 가까울수록 성능이 우수합니다. 이 경우 mAP50은 0.7입니다.
- mAP50-95: 평균 정밀도@0.95 IOU를 나타냅니다. 이는 IOU(Intersection over Union)가 0.95 이상인 경우에만 고려되는 객체 감지 정확도를 측정하는 지표입니다. 0에서 1 사이의 값이며, 1에 가까울수록 성능이 우수합니다. 이 경우 mAP50-95는 0.524입니다.
예측값 생성
2,3번 파라미터가 중요하다.
- Parameters
- source : 예측 대상 이미지/동영상의 경로
- conf : confidence score threshold. default 0.25
- iou : NMS에 적용되는 IoU threshold. default 0.7. threshold를 넘기면 같은 object를 가리키는 거라고 판단.
- save : 예측된 이미지/동영상을 저장할 것인지 설정. default False
- save_txt : Annotation 정보도 함께 저장할 것인지 설정. default False
- save_conf : Annotation 정보 맨 끝에 Confidence Score도 추가할 것인지 설정. default False
- line_width : 그려지는 박스의 두께 설정. default None
model.predict(source='https://images.pexels.com/photos/139303/pexels-photo-139303.jpeg',
save=True, save_txt=True, line_width=2)
model.predict(source='https://images.pexels.com/photos/139303/pexels-photo-139303.jpeg',
conf=0.5
iou=0.5
save=True, save_txt=True, line_width=2)conf를 높이면, 물체들의 총 박스의 수가 줄어든다.
iou를 낮추면, 한 사람에 박스가 2개이던 사람의 박스가 1개로 줄어든다.
그래서 적절하게 threshold 조절을 해야 한다.
conf는 낮아도 박스가 겹쳐져서 그리는 현상을 없게 하려면 iou를 낮춰라.
그러면 항상 ms coco 데이터셋으로만 학습해야 하는가?
이제 데이터 셋을 가져 와서 사용하는 법에 대해서 배워야 한다.
데이터 셋 가져와 사용하기
Roboflow : Universe
Computer Vision
End-to-End 개발 가능
Annotation
Dataset split
Preprocessing
Augmentation
Training 등등
Roboflow : projects
왼쪽를 눌러서 workspace를 새로 생성하고, 이름을 적는다.
workspace는 데이터 셋을 직접 만드는 곳이다.
어떠한 목적인지에 대해서 다르다.
프로젝트를 만드는데, annotation group
persons-dog-cat 이런 걸로 넣는다.
그리고 나서 프로젝트가 만들어지면, 이미지 파일을 업로드할 수 있다.
우측 상단의 save and continue를 누른다.
auto label - 자동으로 해준다.
roboflow labeling - 유료. 박스 하나당 4센트
manual labeling - 수동 라벨링
assign image를 한다.
그러면 annotate 화면으로 이동된다.
start annotating을 클릭하면, 화면이 좀 달라진다.
annotate를 만들기
b 누르고 드래그
bounding box를 그리면 라벨 부여가 가능하다.
ctrl 누르고 이동 가능하다.
자동 저장이 된다.
그렇게 box를 치면 , add 1 image to dataset를 할 수 있다.
그리고 나서 한 개의 이미지를 어떻게 스플릿 할 것인지에 대해 묻는다.
그리고 우측 상단에 create new version 을 누르면, sorce image, 스플릿, 전처리(preprocessing) 할 수 있다.
이미지 데이터에 대해서 어떻게 할 것인지에 대해서도 보여준다.
auto orient, resize, 모자이크 기법 등등
auto orient 모자이크 기법
서로 다른 이미지 4장을 섞어서 하나의 이미지로 만들고 학습.
모델의 robust를 늘린다.
전처리는 auto orient.
augmentation options는 또 따로 있다.
rotation, shear (비스듬히 강조-평행사변형)
cutout도 robust를 늘리기 위한 것.
모자이크는 yolo 모델을 쓸 때 기본적으로 적용된다.
그렇기에 모자이크도 augmentation 과정에서 쓸 수 없다.
yolov8에서 cutout도 쓰지 말라고 써져 있다.
마지막으로 create를 할 수 있다.
export dataset 누르면 , yolo 시리즈가 정말 많은데, yolov8로 export를 하면 된다.
폴더 살펴보기
image와 labels들어오면 labeling 된 정보가 보인다.
class =0 -> xy wh
data yaml이 나온다.
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 1
names: ['persons']
roboflow:
workspace: dream-space-m1ntv
project: avile5
version: 1
license: CC BY 4.0
url: https://universe.roboflow.com/dream-space-m1ntv/avile5/dataset/1
names에 class는 순서대로 넣어줘야 한다.
https://universe.roboflow.com/
universe로 가면, 거기에 데이터셋이 많다.
universe에서 코드를 복사해서 붙여넣으면, api key를 불러와서 노트에 붙여넣을 수 있다.
!pip install roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="TLg5uuY0RQ7ikgDojCkX")
project = rf.workspace("azami-youssef").project("test_project-3cocv")
version = project.version(2)
dataset = version.download("yolov8")
test data의 yaml 데이터
names:
- Arbitre
- Ballon
- Football
- Gardien
- Joueur
nc: 5
roboflow:
license: CC BY 4.0
project: test_project-3cocv
url: https://universe.roboflow.com/azami-youssef/test_project-3cocv/dataset/2
version: 2
workspace: azami-youssef
test: ../test/images
train: test_project-2/train/images
val: test_project-2/valid/images
그런데 이걸 그대로 돌리면 에러가 난다.
데이터셋의 경로를 수정하거나 & yaml 파일의 경로를 수정해야 한다.
datasets_dir를 바꿔줘야 한다.
!pip install ultralytics
from ultralytics import YOLO, settings
settings
settings['datasets_dir'] = '/content/'
settings.update()
settings
yaml의 경로를 그렇게 수정해주면 된다.
import yaml
with open('/content/futbol-players-7/data.yaml', 'r+') as f:
film = yaml.load(f, Loader=yaml.FullLoader)
# display(film)
film['train'] = './train/images/'
film['val'] = './valid/images/'
yaml.dump(film, f)모델 구조만 빌려와서 사용해보기
overriding model.yaml nc=80 with nc=5
coco는 80개 분류인데, 5개만 분류하는 걸로 덮어씌워졌다는 의미이다.
model_scratch = YOLO(model='yolov8n.yaml', task='detect') #모델 선언
model_scratch.train(data='/content/futbol-players-7/data.yaml', #모델 학습
epochs=100,
patience=5,
seed=2024,
pretrained=False,
)
model_scratch.predict(source=image_path, stream=False, save=True) #예측
모델 구조에 가중치 사용해보기
pretrained를 True로 놓으면 된다.
model_transfer = YOLO(model='yolov8n.pt', task='detect')
model_transfer.train(data='/content/futbol-players-7/data.yaml',
epochs=1,
patience=5,
seed=2024,
pretrained=True,
)
image_path = 'https://www.telegraph.co.uk/content/dam/football/2019/08/12/TELEMMGLPICT000206209364_trans_NvBQzQNjv4BqK3Ytq28vYzV8vgytz3tt20cdhPuOVqLHI0GKTHeusDU.jpeg'
model_transfer.predict(source=image_path, save=True)
roboflow 서버가 날아가는 경우도 있으니, 백업은 중요하다.
결과는 runs /detects폴더에 나온다.
trains/ results.png가 만들어진다. -> 훈련 결과

ybat master
그 이외에 ybat으로도 annotate 할 수 있다.
classes라는 txt 파일을 하나 만들어서,
person
car
dsa
이렇게 적어주고, 이미지랑 classes 를 직접 지정할 수 있다.
요약정리
Yolo v8
issue : 직접 설치해야 한다.
roboflow community
1. 남의 데이터셋 가져다가 써보기
2. 직접 데이터셋 구성하기 : 문제점(server가 취약. Ybat master 툴로 대체할 수 있다)
Object Detection - Bounding Box
Bounding Box - 하나의 object가 담겨 있는 최소 크기의 box
구성요소 : x min, y min, x max, y max, x center, y center, width, height. 즉, 위치 정보이다.
- x,y는 좌표이다. w,h는 크기
- x,y라는 점 하나가 있고, 도형이 있다.
- w,h가 있으면 나머지 좌표를 다 구할 수 있다.
다만, bounding box를 구할 때는 아래로 갈 수록 커진다.
- 왼쪽 위에 x,y로 (3,4)가 있다고 해보자.
- h가 4, w가 5면, (3+w, 4+h) = 8,8이 된다.
- 즉, w쪽으로 x축이고, h쪽으로 y축이다.
Predicted Bounding Box = 구성 요소 : x^,y^,w^,h^(x,y,w,h의 예측값)
x~x^, y~y^이 비슷하다는 의미는 Bounding Box 꼭지점 예측을 잘 한 것이다.
w~w^, h~h^이 비슷하다는 의미는 Bounding Box 크기 예측을 잘 한 것이다.
통합해서, 모델이 object가 있는 위치를 잘 예측한다고 말 할 수 있다.
즉, object detection이라는 건, 물체의 위치 정보를 예측하는 방법이다.
Bounding BOX Regression
연결주의 학파의 관점에서 지도학습이란?
딥러닝 관점에서 error를 줄여나가는 방향으로 w를 업데이트 하는 것
x=5이고, x^=10일 때, error를 잘 줄여 나간다면 x^=5가 될 것이다.
이는 y,w,h도 마찬가지이다.
즉, 위치 정보에 대해서'만' Regression 문제를 풀듯이 접근이 가능하다.
그래서 Object Detection에서
Object Detection - Class Classification
여태까지 해오던 것
실제 Label에 대해서, category를 나눌 때 2가지 방식으로 인코딩을 했다.
- Integer Encoding
- One hot encoding
Predicted - [0.8,0.02,0.1,0.05..] 이런 식으로 담긴다.
bounding Box 안에 object가 있다는 가정 하에, 그때부터는 classification 문제로 접근 가능하다.
그렇게 하면 two-stage image detection이 되는 것이다.
여기서 의문점 : object가 진짜로 bounding box 안에 있기는 한 건지를 모른다.
이에 대한 확신의 정도가 Confidence Score이다.
Object Detection - Confidence Score
Ground Truth Bounding Box가 있다고 하자.
이의 Confidence Score는 1로 고정된다. -> 그 object가 '일단 있다'라고 가정을 무조건 하는 것이다.
그리고 그 Ground Truth Bounding Box를 기준으로, Predicted Bounding Box는 0~1사이의 값을 가진다.
0에 가까울수록, 해당 영역에 물체가 없다고 추측을 한다.
1에 가까울수록, 해당 영역에 물체 있다고 추측을 한다.
그러므로 하나의 object Detection에서 나오는 결과는, x,y,w,h에 대한 예측값 + 분류되는 class 값 + confidence Score 인 것이다.
그럼 CNN은 object Detection에서 어떤 역할을 하는가?
CNN에서 Feature Representation이란?
CNN의 가장 큰 특징은 공간적 특성(위치 정보)를 유지시키면서 Feature를 Representation하는 것이다.
만약 좌상단에만 고양이가 그려져 있고, 나머지는 빈 공간인 그림이 있다고 해보자.
그러면 feature map이 그려질 때, 좌상단에서의 feature map만 계속해서 특징 값이 가져와진다.
그렇게 flatten을 해서, fully conneted layer가 만들어 질때는, 위치 정보의 의미가 없어진다.
그러면 F.C는 무슨 역할을 하는 것인가? -> 분류기의 역할로 구성되는 것이다.
이럴 때는 앞단에서 추출된 위치 정보가 쓰일지 안 쓰일지 조차 모른다.
학습이 정말 잘 되었다고 하자, 이때 CNN의 역할은 무엇인가?
- 유용한 특징 추출
- 위치 정보를 포함하고 보존했을 가능성이 매우 높다.
output은 classification으로 나왔지만, CNN 층 그 자체만 가져다 쓰면 Bounding box regression 문제와 같다.
따라서 object Detection에서 CNN의 역할은, 잘 학습된 위치 정보 분류기의 역할을 해주는 것이다.
Bounding Box에서 Backbone(골자 구조)가, CNN으로 쓰이고, 우리 문제에 맞게 추가/변형을 한다.
이때 추가/변형을 하는 곳을 Head라고 한다.
그래서, Backbone + head라고 한다.
논문 : 어떤 문제의 구조를 끌어다 썼다(Backbone), +head(변형했다) 라고 표현하는 것이다.
과거 ResNet, VGG = Backbone
기본 근간은 결국 CNN 기반의 모델들
중간에 Neck이라는 것도 나오는데, 빼고서라도 Backbone과 head가 object Detection모델에 쓰이는 용어다.
- Backbone: 모델의 기본 골격이 되는 CNN 기반 네트워크를 의미합니다. 예를 들어 ResNet, VGG 등이 Backbone으로 사용될 수 있습니다.
- Head: Backbone에서 추출한 특징 맵을 사용하여 객체의 분류와 바운딩 박스 예측을 수행하는 부분입니다. 문제에 맞게 Backbone 출력을 변형하고 추가 연산을 수행합니다.
- Neck: 때로는 Backbone과 Head 사이에 특징 맵을 재구성하거나 다른 연산을 수행하는 Neck 부분이 추가되기도 합니다.
숙제
1. Object Detection 할 주제 고민
2. 그 주제에 맞는 이미지 수집 및 Annotating
그걸 직접 돌리고, yaml 구성을 해볼 것이다.
3. 미니 프로젝트 대비용 코드 훈련 < hard 할 것이다.
내일 할 것이 2,3번
3번은 시간이 남는다면
영상에 대한 yolo detection
!pip install ultralytics
from ultralytics import YOLO
model = YOLO(model='yolov8s.pt', task='detect')
!mkdir /content/videos
!wget -O /content/videos/01.mp4 https://github.com/DrKAI/image/raw/main/No_Way_This_Happened.mp4
!wget -O /content/videos/02.mp4 https://github.com/DrKAI/image/raw/main/Guy_slips_20th_century_remix.mp4
!wget -O /content/videos/03.mp4 https://github.com/DrKAI/image/raw/main/kid_dream.mp4
result = model.predict(source='/content/videos/',
save=True,
stream=True
)
for r in result :
r.boxes