
티스토리 뷰
어떠한 값을 순차탐색하면 확실히 데이터를 얻을 수 있지만, 모든 데이터를 살펴봐야하는 경우가 있으므로 효율적이지 않다.
그러므로 해시는 어떠한 기준(함수)로 변환한 값을 인덱스로 삼아서,
그 인덱스에 해당하는 배열에 키와 값을 저장해 빠른 데이터 탐색을 제공하는 자료구조다.
여기서 탐색에 특화되었다는 게 중요하다.
리스트 자료구조의 경우, 보통 검색에 O(n), 추가에 O(1)이자만, 여기서는 반대이다.
물론 리스트도 중간 추가면 O(n)이긴 하다. 그러나 차이점을 아는 게 중요하다.
해시의 시간복잡도
삽입(Insert): 평균 O(1), 최악의 경우 O(n)
검색(Search): 평균 O(1), 최악의 경우 O(n)
삭제(Delete): 평균 O(1), 최악의 경우 O(n)
해시의 특징
해시는 키를 통해서 값을 찾을 수 있지만 값으로 키를 찾을 수는 없다.
찾고자 하는 값을 O(1)로 바로 찾는다. -> 키 자체가 값이 있는 인덱스를 특정하므로 가능하다.
만약 두 리스트에서 하나의 리스트에 대비되는 값을 찾아야 한다면, O(n)만큼의 검색을 한 후, 그 값으로 다른 리스트의 인덱스에서 찾아야 한다.
그러나 해시는 키를 해시 함수에 집어넣고, 나온 그 값으로 두 번째 리스트에서 값을 찾는다.
버킷
해시 테이블은 키-값 형태로 데이터를 저장하고, 해시 테이블의 각 행은 버킷이라고 불린다.
버킷은 해시 충돌을 처리하는 구조 중 하나로, 동일한 키 값을 가진 여러개의 키-쌍 값을 저장한다.
버킷은 주로 다음과 같은 방법으로 구현된다.
- 체이닝(Chaining): 체이닝은 가장 일반적인 해시 충돌 처리 방법 중 하나로, 해시 테이블의 각 슬롯에 연결 리스트를 사용하여 여러 키-값 쌍을 저장하는 방법입니다. 각 슬롯이 버킷 역할을 하며, 해당 인덱스에 해시 충돌이 발생하면 연결 리스트에 추가하여 저장합니다.
- 다른 자료 구조 사용: 연결 리스트 외에도 버킷으로 사용할 수 있는 다른 자료 구조를 사용하여 해시 충돌을 처리할 수 있습니다. 예를 들어, 배열이나 트리 구조 등을 사용할 수 있습니다.
해시 함수
해시 함수를 구현하려면 어떻게 해야 할까?
해시 함수가 변환한 값은 해시 테이블의 인덱스 크기를 넘어가면 안된다. 즉, 최대 반환 크기가 정해져야 한다.
두 번째로 해시 함수가 변환한 값의 충돌은 없을 수는 없으니 최소한으로 발생해야 한다.
서로 다른 두 키에 대해 해싱 함수를 적용했을 때, 결과가 같은 것을 충돌이라고 한다.
자주 사용하는 해시 함수
- 나눗셈법
소수로 나눈 나머지를 활용한다. 소수로 나누면 충돌이 적다는 걸 이용한다.
나눗셈법의 해시 테이블 크기는 키 값으로 들어가는 값이 된다(0~해당 값-1 이므로)
- 곱셈법
나눗셈법은 아주 큰 소수를 사용해야 하는데, 큰 소수를 구하기 쉽지 않다.
곱셈법은 소수 연산을 활용하지 않고, 나머지 연산만 활용한다.
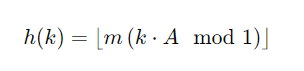
A는 황금비이고, m은 해시 테이블의 크기(버킷의 수)이다.
키에 황금비를 곱하고, 그 값에 모듈러 1을 취하면 정수 부분을 버리고 소수 부분만 취해진다.
그러면 해당 결과 값은 0.xx..형태의 소수가 된다.
이런 소수 형태의 값을 가지고, 해시 테이블의 크기(버킷의 수)를 곱한 후에 정수 부분만 취하는(내림) 연산을 하면 해시 테이블의 인덱스 값이 나온다.
그러면 0~m-1에 매치할 수 있다.
무슨 말이냐 하면, 다른 수 k1,k2에 대해서 소수 부분이 똑같을 수는 거의 없으니, 그 소수 부분에 m을 곱해서 구분하겠다는 뜻이다.
문자열 해싱
해싱의 핵심.
해싱을 사용하는 이유라 해도 과언이 아니다.
hash = (s[0] + s[1] * p +s[2]*p^2....s[n-1]*p^(n-1)) % m
키의 자료형이 문자열일 때 사용할 수 있는 해싱
p는 31이고, m은 역시나 최대 버킷의 수이다.
p가 31인 이유는 홀수이면서 메르센 소수(2^n-1) 형식으로 표시할 수 있는 숫자 중에 소수인 수이기 때문이다.
메르센 소수로 하면 해시에서 충돌이 줄어든다는 연구 결과가 있다.
알파벳은 총 26개이다. 그러므로 1~26을 a~z로 대응할 수 있다. 이는 매치표이다.
만약 a가 0번째 인덱스에 들어 가 있다면, 매치표의 숫자인 1(=s[0])로 변경한다.
그러면 s[0]*p^0는 1*1이므로 1이 된다.
만약 l이 3번째 인덱스에 들어가 있다면, l은 매치표에서 12번째이므로 s[3]=12이다.
그래서 12*31^3이 된다.
그렇게 해서 다 더하면 하나의 문자열에 대해 백만 단위의 수가 나온다.
이러면 오버 플로우가 일어난다.
그러므로 m으로 각각 나눠서 문자열 해싱을 수정해야 한다.
hash = (s[0]%m + s[1]%m * p +s[2]%m *p^2....s[n-1]%m*p^(n-1))%m
충돌 처리
체이닝
위에서 언급했던 충돌 처리를 잘 해야 한다.
체이닝은 해시 테이블에 충돌이 발생하면 해당 버킷에 링크드 리스트로 같은 해시값을 가지는 데이터를 연결한다.
한마디로 해당 인덱스에서만 링크드 리스트가 생겨 꼬리표가 있는 리스트가 된다.
그러나 단점이 있다.
충돌이 많아질수록 링크드 리스트의 길이가 길어지고, 공간 활용성이 떨어진다.
또한 검색 성능이 떨어진다. 당연하게도 링크드 리스트 안의 값에서 또 검색을 해야하기 때문이다.
개방 주소법
체이닝에서 링크드 리스트로 처리한 것과 달리, 빈 버킷을 찾아 충돌값을 삽입한다.
메모리가 빈 공간을 찾는 것과 비슷한 방식
선형 탐사 방식으로 빈 버킷을 찾을 때까지 일정한 간격으로 이동한다. 보통 간격은 1로 하는 게 일반적이다.

N은 수용할 수 있는 최대 버킷이다. 넘으면 안되므로 모듈러 연산을 적용한다.
j는 간격이다. 충돌이 발생할 때마다 j가 1씩 증가한다.(그곳에 값이 있으므로)
h(key)의 값은 해당 값을 원래 저장할 인덱스
그런데 이 방법도 단점이 있다. 충돌이 발생한 값끼리 모이는 영역이 생긴다(클러스터)
군집이 생기면 해시값이 겹칠 확률이 올라간다. 그래서 이를 방지하기 위해 제곱수만큼 이동해서 탐사하는 방식도 있다.
이중 해싱 방식
이중 해싱 방식은 해시 함수를 2개 사용한다. 때에 따라 해시 함수를 N개 늘리기도 한다.
두 번째 해시 함수의 역할은 첫 번째 해시 함수로 충돌이 발생하면 해당 위치를 기준으로 어떻게 위치를 정할지 결정하는 역할이다.
h1 이 1차 함수, h2가 해시 2차 함수

선형 탐사 함수랑 비슷한데, j에 h2를 곱한다.
클러스터를 줄이기 위해서 m을 제곱수로 하거나 소수로 한다.
점프하는 위치를 다르게 하기 위함이다.
실제 코딩 테스트 문제에서 해시 문제의 핵심은 키와 값을 매핑하는 과정이다.
빈번한 검색을 해야 하거나 특정한 정보와 매핑하는 값의 관계를 확인해야 하는 작업이 문제에 있다면 해시를 고려해야 한다.