
티스토리 뷰
지난 포스팅에서 배웠던 LangGraph를 활용하여 기본적인 워크플로우를 제작한다.
이론은 간단하기에, 재정정보 AI 검색 알고리즘 경진대회에서 썼던 코드를 리팩토링하여 사용하였다.
자세한 코드는 이곳에서 볼 수 있다.
DB 만들기
일단 예제와 다르게 retriever와 DB가 들어 있는 FAISS를 만든다.
왜냐하면 LangGraph의 시작은 결국 Retriever 부터 시작하기 때문에 그렇다.
그렇기에 DB는 일단 만들어져 있어야 한다.
대략적으로 요약하자면, pdf를 가져와서 청킹하고 임베딩 한다고 생각하면 된다.
def process_pdfs_from_dataframe(df, base_directory):
"""딕셔너리에 pdf명을 키로해서 DB, retriever 저장"""
pdf_databases = {}
unique_paths = df['Source_path'].unique()
cnt=0
for path in tqdm(unique_paths[:1], desc="Processing PDFs"):
# 경로 정규화 및 절대 경로 생성
normalized_path = normalize_path(path)
full_path = os.path.normpath(os.path.join(base_directory, normalized_path.lstrip('./'))) if not os.path.isabs(normalized_path) else normalized_path
pdf_title = os.path.splitext(os.path.basename(full_path))[0]
print(f"Processing {pdf_title}...")
# PDF 처리 및 벡터 DB 생성
chunks = process_pdf(full_path,pdf_title)
db = create_vector_db(chunks, model_path=args.embed_model,cnt=cnt)
Okt_bm25_retriever = OktBM25Retriever.from_documents(chunks)
Okt_bm25_retriever.k = 5
faiss_retriever = db.as_retriever(search_kwargs={'k': 5},)
retriever = EnsembleRetriever(
retrievers=[Okt_bm25_retriever, faiss_retriever],
weights=[args.bm25_w, args.faiss_w],
search_type="mmr",
search_kwargs={'k': 5},
)
# 결과 저장
pdf_databases[pdf_title] = {
'db': db,
'retriever': retriever
}
cnt+=1
return pdf_databases
LangGraph 정의하기
그런 다음에는 프로세스 순서를 정의한다.
해당 코드에서는 Retriever 노드가 있어야 하고, LLM answer 노드만 있으면 된다.
그렇기에 노드에 들어갈 함수들은 다음과 같이 정의된다.
def retrieve_document(state: GraphState) -> GraphState:
source = normalize_string(state["source"])
normalized_keys = {normalize_string(k): v for k, v in test_pdf_databases.items()}
retriever = normalized_keys[source]['retriever']
compressor = CrossEncoderReranker(model=model, top_n=5)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever)
retrieved_docs = compression_retriever.get_relevant_documents(state["question"])
formatted_docs = format_docs(retrieved_docs)
return GraphState(
question=state["question"],
source=state["source"],
context=formatted_docs,
retriever=compression_retriever
)
# 답변 생성 노드 함수
def generate_answer(state: GraphState) -> GraphState:
template = """
{question}
{context}
주어진 질문에만 답변하세요.
답변:
"""
prompt = PromptTemplate.from_template(template)
rag_chain = (
{"context": lambda x: state["retriever"] | reorder_documents, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
full_response = rag_chain.invoke(state["question"])
return GraphState(
question=state["question"],
source=state["source"],
context=state["context"],
answer=full_response
)
하고자 한다면, State를 또 따로 정의해서 compressor 노드만 또 따로 뺄 수도 있고, prompt 노드도 뺄 수 있다.
여기서는 간단하게 한 것이기에 그렇게 까지는 하지 않았다.
아무튼 이렇게 정의가 되었다면 예제처럼 workflow에서 노드와 엣지를 만들어주면 된다.
workflow = Graph()
workflow.add_node("retrieve", retrieve_document)
workflow.add_node("answer", generate_answer)
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "answer")
workflow.add_edge("answer", END)
# Compiler
app = workflow.compile()
그리고 해당 그래프를 실행해보면 다음과 같이 밋밋한 그래프가 나온다.

결과물도 잘 나온다.

단방향이지만, 이걸 위해서 LangGraph를 쓰는 건 아니다.
그렇기에 아주 간단한 relevance check를 추가했다.
from langchain_upstage import UpstageGroundednessCheck
# 업스테이지 문서 관련성 체크 기능을 설정합니다. https://upstage.ai
upstage_ground_checker = UpstageGroundednessCheck(api_key="")
# 업스테이지 문서 관련성 체크를 실행합니다.
def relevance_check(state: GraphState) -> GraphState:
# 관련성 체크를 실행합니다. 결과: grounded, notGrounded, notSure
response = upstage_ground_checker.run(
{"context": state["context"], "answer": state["answer"]}
)
return GraphState(
relevance=response,
context=state["context"],
answer=state["answer"],
question=state["question"],
)
def is_relevant(state: GraphState) -> GraphState:
if state["relevance"] == "grounded":
return "관련성 O"
elif state["relevance"] == "notGrounded":
return "관련성 X"
elif state["relevance"] == "notSure":
return "확인불가"그리고 나서는 메모리 설정만 graph에 추가해주었다.
workflow.add_conditional_edges(
"relevance_check", # 관련성 체크 노드에서 나온 결과를 is_relevant 함수에 전달합니다.
is_relevant,
{
"관련성 O": END, # 관련성이 있으면 종료합니다.
"관련성 X": "retrieve", # 관련성이 없으면 다시 답변을 생성합니다.
"확인불가": "retrieve", # 관련성 체크 결과가 모호하다면 다시 답변을 생성합니다.
},
)
# 시작점을 설정합니다.
workflow.set_entry_point("retrieve")
# 기록을 위한 메모리 저장소를 설정합니다.
memory = MemorySaver()
# 그래프를 컴파일합니다.
app = workflow.compile(checkpointer=memory)
그리고 노드 연결도 다음과 같이 바꿔주어야 한다.
# 각 노드들을 연결합니다.
workflow.add_edge("retrieve", "llm_answer") # 검색 -> 답변
workflow.add_edge("llm_answer", "relevance_check") # 답변 -> 관련성 체크
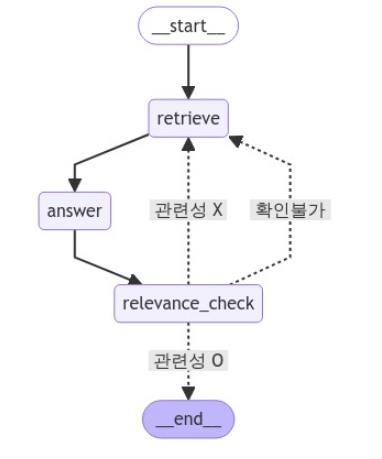
그럼 다음과 같이 LangGraph의 원형이 완성된 것을 볼 수 있다.
이렇게 Agentic Workflow를 가진 RAG를 만들 수 있다.

답변을 보면 relevance도 잘 나오는 걸 확인할 수 있다.