

티스토리 뷰
https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=107
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
aihub.or.kr
사용한 데이터는 노인 음성 대화 데이터.
지난시간에 만든 데이터 전처리를 포함해서, Pre-Trained 모델에 Validation 데이터 중 1000개의 데이터를 포함해서 먼저 간이 CER 측정을 시도했다.
!pip install transformers datasets jiwer librosa
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
import os
import csv
from jiwer import cer
import warnings
# 경고 무시 설정
warnings.filterwarnings("ignore", category=FutureWarning)
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
)
def load_reference_from_csv(csv_file):
references = {}
with open(csv_file, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
if row['audio_file'][-1:]=='p':
row['audio_file']= row['audio_file'][:-1]
elif row['audio_file'][-3:]=='WAV':
row['audio_file']= row['audio_file'][:-3]+'wav'
references[row['audio_file']] = row['stt_text']
return references
def process_wav_folders(folder_paths, reference_csv):
all_hypotheses = []
all_references = []
# 참조 텍스트 로드
references = load_reference_from_csv(reference_csv)
print(len(references))
file_count = 0
for folder_path in folder_paths:
for root, _, files in os.walk(folder_path):
for file in files:
if file.endswith('.wav'):
wav_path = os.path.join(root, file)
# WAV 파일 처리
result = pipe(wav_path,generate_kwargs={"language": "korean"})
hypothesis_text = result["text"]
# print(file)
# 참조 텍스트 추가
if file in references:
reference_text = references[file]
all_references.append(reference_text)
all_hypotheses.append(hypothesis_text)
file_count += 1
# 진행 상황 출력
if file_count % 10 == 0:
print(f"{file_count}개 파일 처리 완료")
if file_count % 100 == 0:
current_cer = cer(" ".join(all_references), " ".join(all_hypotheses))
print(f"{file_count}개 파일 처리 완료. 현재 CER: {current_cer:.4f}")
else:
print(f"경고: {file}에 대한 참조 텍스트를 찾을 수 없습니다")
return all_references, all_hypotheses
# 메인 실행 부분
if __name__ == "__main__":
folder_paths = [
# "/kaggle/input/val-wav/Validation/AI스피커",
# "/kaggle/input/val-wav/Validation/AI챗봇",
"/kaggle/input/val-wav/Validation/스튜디오",
# "/kaggle/input/val-wav/Validation/음성수집도구"
]
reference_csv = "/kaggle/input/val-wav/audio_text_pairs_with_labels.csv" # 참조 텍스트가 있는 CSV 파일 경로
references, hypotheses = process_wav_folders(folder_paths, reference_csv)
# 전체 CER 계산
overall_cer = cer(" ".join(references), " ".join(hypotheses))
print(f"전체 CER: {overall_cer:.4f}")
# 결과를 파일로 저장
with open("transcription_results.txt", "w", encoding="utf-8") as f:
for ref, hyp in zip(references, hypotheses):
f.write(f"참조: {ref}\n")
f.write(f"가설: {hyp}\n")
f.write("\n")
print("결과가 transcription_results.txt 파일에 저장되었습니다.")


100회마다 측정했을 때, 평균을 내면 베이스라인은 대략 7% 정도.
아래는 띄어쓰기를 없앴을 때의 베이스라인이다.
이 베이스라인에 비교해서 파인튜닝 후의 효과를 볼 것이다.
CSV 파일이 있고, wav 파일을 대략적으로 표시해보면 다음과 같다.
D:\데이터\자유대화 음성(노인남녀)\Training>python check.py
Folder '[라벨]1.AI_챗봇' contains 340851 files.
Folder '[라벨]2.음성수집도구' contains 595637 files.
Folder '[라벨]3.스튜디오' contains 133387 files.
Folder '[라벨]4.AI스피커' contains 80318 files.
Folder '[원천]1.AI_챗봇' contains 340851 files.
Folder '[원천]2.음성수집도구' contains 595637 files.
Folder '[원천]3.스튜디오' contains 133387 files.
Folder '[원천]4.AI스피커' contains 80318 files.
총 1,150,193개.
따라서 50000개씩 묶어 단계적 파인튜닝을 진행한다.
가장 참고하기 좋은 블로그는 아래 블로그이다.
[NLP] OpenAI Whisper Fine-tuning for Korean ASR with HuggingFace Transformers (velog.io)
웬만한 코드들은 위의 블로그에서 올린 코드와 다 똑같으나, 여기서는 csv를 쓰기 때문에 바뀐 코드들만 보자
전처리 함수 코드 변경
from transformers import WhisperFeatureExtractor
# 파인튜닝을 진행하고자 하는 모델의 feature extractor를 로드
model_id = "openai/whisper-large-v3"
feature_extractor = WhisperFeatureExtractor.from_pretrained(model_id)model_id를 하드 코딩에서 바꿔주었다.
import pandas as pd
# 2. 텍스트 파일 경로 취합
path = "/kaggle/input/train-wav/audio_text_pairs_with_labels.csv"
df = pd.read_csv(path)
df = df[df['label']=='[라벨]1.AI_챗봇']
# 레이블 데이터에는 json 데이터가 폴더별로 하나씩 있으므로 txt 파일만을 골라낸다.
# labeled_data_list = sorted([file for file in labeled_data_list if file.endswith(".txt")])txt 대신 csv에서 불러오는 형식으로 바꿔주었다.
# audio_file과 raw_data에서 파일 이름만 추출하여 비교
df['raw_filename'] = df['raw_data'].apply(lambda x: os.path.basename(x))
df['match'] = df['audio_file'] == df['raw_filename']
# 결과 출력
print(df[['audio_file', 'raw_data', 'match']])
그러면 각각의 audio file과 raw_data에서 파일을 추출하여 비교해보고, df로 만들 수 있다.
핵심 함수
음성 데이터 전처리에서 핵심 함수는 다음과 같다.
from datasets import Dataset, DatasetDict
from datasets import Audio
# 오디오 파일 경로를 dict의 "audio" 키의 value로 넣고 이를 데이터셋으로 변환
# 이때, Whisper가 요구하는 사양대로 Sampling rate는 16,000으로 설정한다.
ds = Dataset.from_dict({"audio": [path for path in df["raw_data"]],
"transcripts": [transcript for transcript in df["transcript"]]}).cast_column("audio", Audio(sampling_rate=16000))
cast_column 함수가 샘플링 rate을 16000으로 맞춰주고, array를 생성해주기 때문에 정말 좋다.
def prepare_dataset(batch):
# 오디오 파일을 16kHz로 로드
audio = batch["audio"]
# input audio array로부터 log-Mel spectrogram 변환
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
# target text를 label ids로 변환
batch["labels"] = tokenizer(batch["transcripts"]).input_ids
return batch
# 데이터 전처리 함수를 데이터셋 전체에 적용
low_call_voices = datasets.map(prepare_dataset, remove_columns=datasets.column_names["train"], num_proc=None)
이 함수도 매우 중요하다. feature_extractor의 경우, 말이 많은 사람이 있고, 적은 사람이 존재한다.
그런데 딥러닝을 할 떄는 길이를 전부 같게 맞춰줘야 행렬의 input이 일정하므로, 이 함수가 패딩을 해주는 역할을 한다.
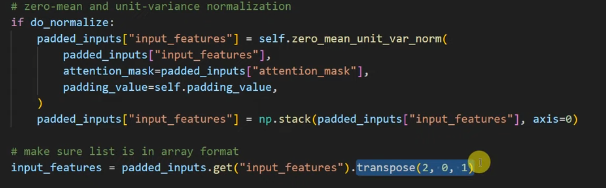
그리고 나서 Transpose를 해주는데, 2,0,1 순서로 만든다.
이 순서로 만드는 이유는 [1,2,3] , [4,5,6]의 2가지 피처가 있으면, 이게 결국 [1,], [2,], [3,] 과 [4,], [5,] [6,] 의 3*1로 각각 바뀌게 된다.
그러면 2(개)*3(행)*1(열)이다.
거기서 2번째를 가져오면 1이고, 0번째를 가져오면 2이고, 1번째를 가져오면 3이다.
즉, 1(개) * 2(행) * 3(열) 이 되고, 각각은 [ [1,2,3] , [4,5,6]]이 된다.
이렇게 번거롭게 하는 건, 처리하다가 사이즈가 깨질 수가 있는데 그 깨지는 걸 방지하면서 한개의 input으로 만들기 위함이다.
만약에 자체적으로 읽어들여서 변환한다 하면 이렇게도 할 수 있다.
from scipy.io.wavfile import read
import numpy as np
def prepare_dataset(batch):
# 오디오 파일을 16kHz로 로드
audio = batch["audio"]['path']
_, data = read(audio)
audio_array = np.array(data, dtype=np.float32)
# input audio array로부터 log-Mel spectrogram 변환
batch["input_features"] = feature_extractor(audio_array, sampling_rate=batch["audio"]["sampling_rate"]).input_features[0]
# target text를 label ids로 변환
batch["labels"] = tokenizer(batch["transcripts"]).input_ids
return batchread를 써서 float 32로 변환하는 코드이다.
만약 따로 함수를 써서 배치처리까지 한번에 하고 싶다면 이렇게 해도 된다.
Data Collator
만들어진 데이터를 텐서로 바꿔주는 코드이다.
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# 인풋 데이터와 라벨 데이터의 길이가 다르며, 따라서 서로 다른 패딩 방법이 적용되어야 한다. 그러므로 두 데이터를 분리해야 한다.
# 먼저 오디오 인풋 데이터를 간단히 토치 텐서로 반환하는 작업을 수행한다.
input_features = [{"input_features": feature["input_features"]} for feature in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# Tokenize된 레이블 시퀀스를 가져온다.
label_features = [{"input_ids": feature["labels"]} for feature in features]
# 레이블 시퀀스에 대해 최대 길이만큼 패딩 작업을 실시한다.
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# 패딩 토큰을 -100으로 치환하여 loss 계산 과정에서 무시되도록 한다.
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
# 이전 토크나이즈 과정에서 bos 토큰이 추가되었다면 bos 토큰을 잘라낸다.
# 해당 토큰은 이후 언제든 추가할 수 있다.
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
평가 함수
평가 함수는 한국어에 맞는 CER로 진행한다.
def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# pad_token을 -100으로 치환
label_ids[label_ids == -100] = tokenizer.pad_token_id
# metrics 계산 시 special token들을 빼고 계산하도록 설정
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
label_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)
cer = 100 * metric.compute(predictions=pred_str, references=label_str)
return {"cer": cer}
또한 한국어 설정을 따로 해주고 토큰 억제를 풀어준다.
이는 언어 설정에서 괜히 오류가 나지 않고 정확도를 높이기 위함이다.
model.config.forced_decoder_ids = None
model.config.suppress_tokens = []
이제 설정은 끝났으니 Train만 하면 된다.
Seq2Seq trainer를 사용한다.
개인적으로 Step이 많다면 save_step은 많이 잡아주자. 용량이 저장될 때 생각보다 많다.
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="repo_name", # 원하는 리포지토리 이름을 임력한다.
per_device_train_batch_size=16,
gradient_accumulation_steps=1, # 배치 크기가 2배 감소할 때마다 2배씩 증가
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000, # epoch 대신 설정
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=8,
predict_with_generate=True,
generation_max_length=225,
save_steps=50000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
metric_for_best_model="cer", # 한국어의 경우 'wer'보다는 'cer'이 더 적합할 것
greater_is_better=False,
push_to_hub=True,
)
다음 시간에는 이렇게 Train한 모델을 가지고 CER 측정을 또 해보도록 하겠다.