
티스토리 뷰
지난 글과 이어지는 글이다.
지난 글에 AI 허브에서 데이터가 개방되지 않았다고 했는데, 정말 다행스럽게도 프로젝트가 시작되지 얼마 되지 않아 모델과 데이터가 열렸다!(!!!!)
너무 신나했더니 팀원들이 그렇게나 좋냐며 말했다.
왜냐하면 지난 글에서 분명 accuracy는 높게 달성했지만, 실제 Test 스코어 상에서는 너무 성능이 떨어졌기 떄문이다.
한글로 번역해서 한글 데이터 셋으로 Kcelectra를 쓰기도 했지만, 역시나 augmentation을 했어도 너무 성능이 떨어져서 이걸 어떻게 해야 하던 찰나에, 데이터셋이 열린 것이다.
그래서 일단은 제공되는 모델을 실험해보기로 했따.
데이터셋은 13만개 정도이므로, GPU를 넣는다면 어느정도 될 수 있으나, 이미 성능이 좋다면 이미 있는 모델을 쓰는 게 더 좋다.
전부 Docker 파일로 되어 있어서 docker에서 뽑아서 만들었다.
문제라면 이제 모델마다 환경설정이 다르다는 것.
하나는 safetensor를 쓰고, 다른 하나는 ckpt를 쓴다.
그래도 최대한 이미 있는 코드들을 잘 갈무리해서 결국에는 django를 통해 API로 만들었다.
결과는?
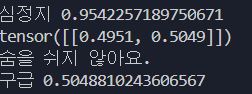
성공이다.
중간에 tokenizer가 불러와지지 않아서 조금 에러가 있었지만, 그래도 다행히 해당하는 tokenizer 파일을 연동해서 아주 좋은 모델 결과를 얻었다.
짧은 문장을 했을 때도 이 정도로 잘 인식하는 것이면, 아주 좋은 모델이 될 것이다.
추가적인 fine_tuning도 해보고, 더 많은 트라이를 해봐야 할 거 같다.
아주 기분이 좋아졌다. 4주차에는 멀티 모달 모델도 API로 만들기 위해 달려가야겠다.